零散知识点整理.md

文章目录
项目应用
什么是 AOP
在理解 AOP 之前,先提个东西,它在 Go 中叫中间件,也就是常说的 middleware。在其他语言中有叫做的 plugin、handler、filter、interceptor 等等。
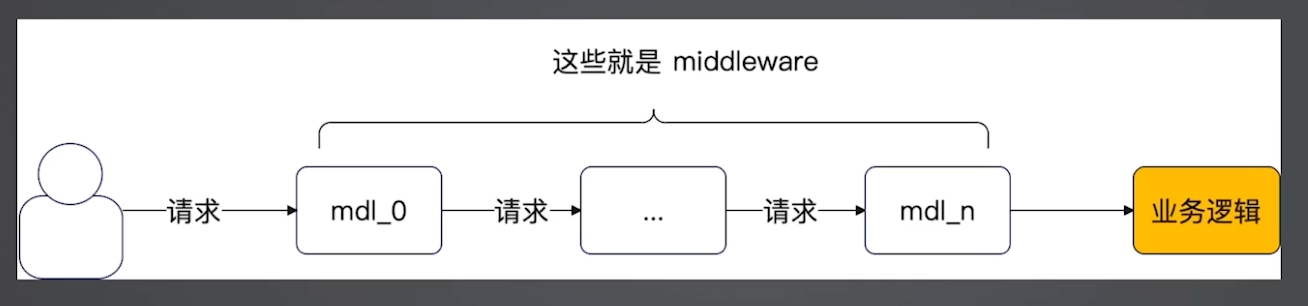
从图中可看到 middleware 是在处理请求发出之后,在业务处理之前锁执行的操作,所以它通常适合用来解决一些所有业务都关心的问题,比如跨域、日志、鉴权等。
这个解决方案就是 AOP (Aspect-Oriented Programming) 解决方案。
无状态的HTTP协议
什么叫做HTTP是无状态的?
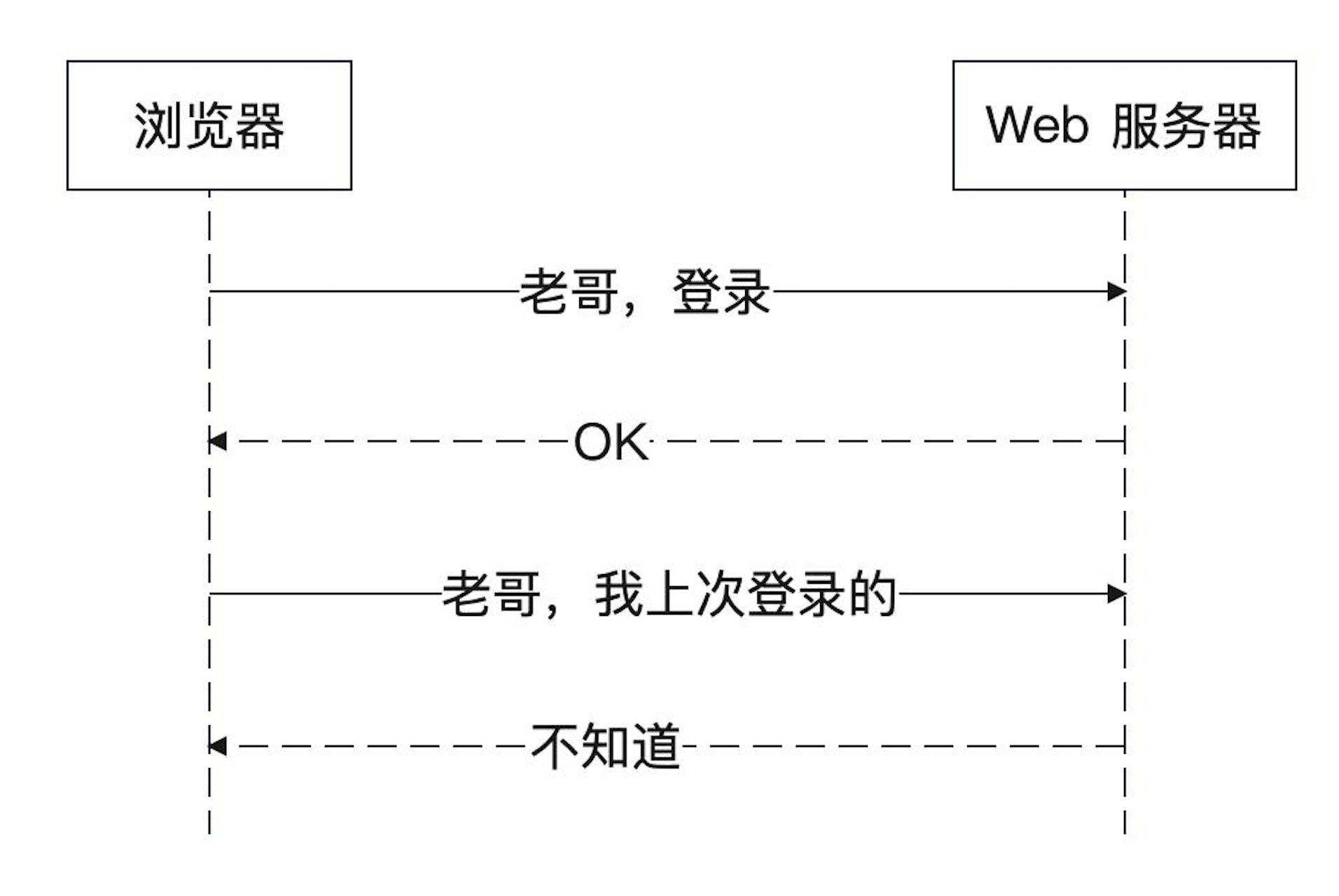
连续发两次请求,HTTP并不知道这两个都是你发的。也就是,它没办法将上一次请求和这一次请求关联起来。那怎么才能知道两次的请求是有关联的呢?这就需要有一种机制,记录一下这个状态。
于是就有两个东西:Cookie 和 Session。
Cookie
什么是 Cookie ?
浏览器存储一些数据到本地,这些数据就是 Cookie。Cookie本质上就是存储在我们电脑本地上的键值对。但因为 Cookie 是放在浏览器本地的,所以它不安全。
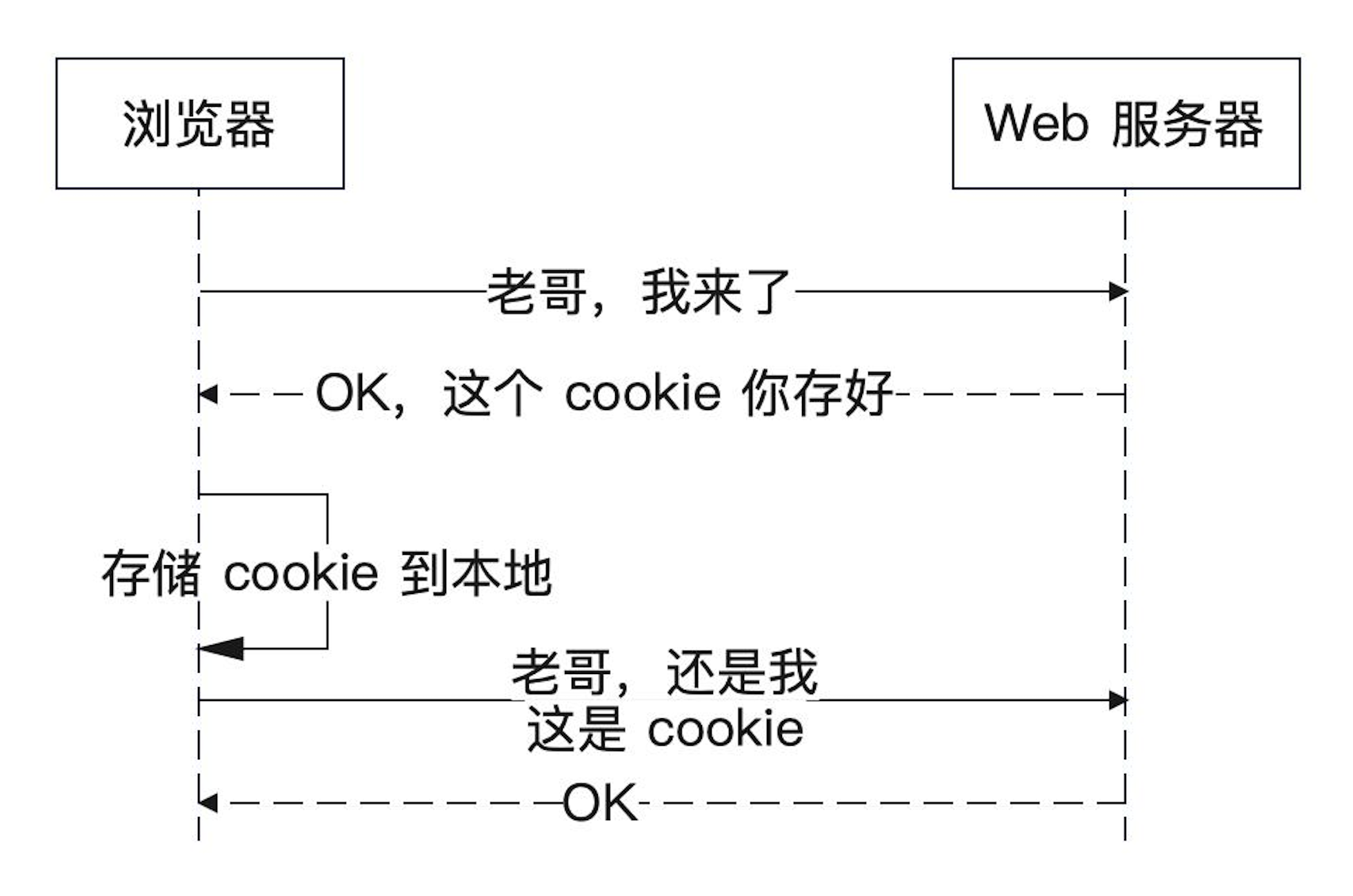
比如可以通过一些工具查看本地浏览器的 Cookie,它不安全是因为我们可以更改 Cookie 的值,如果我们的电脑中了病毒,本地的Cookie被不法分子获取就会很危险:
Cookie 最大的问题就是它的不安全,比如用户很多的网站登录态都是放在 Cookie 中的,如果攻击者拿到Cookie,他就可以伪装成用户。
Cookie 的关键配置
- Domain:也就是Cookie可以用在什么域名下,按照最小化原则来设定。
- Path:Cookie可以用在什么路径下,同样按照最小化原则来设定。
- Max-Age和Expires:过期时间,只保留必要时间。
- Http-Only:设置为true的话,那么浏览器上的JS代码将无法使用这个Cookie。永远设置为true。Secure:只能用于HTTPS协议,生产环境永远设置为true。
- SameSite:是否允许跨站发送Cookie,尽量避免。
Session
什么是 Session ?
因为Cookie本身不安全的特性,所以大部分时候,我们都只在Cookie里面放一些不太关键的数据。关键数据我们希望放在后端,这个存储的东西就叫做Session。比如在登录中,我们就可以通过Session来记录登录状态。
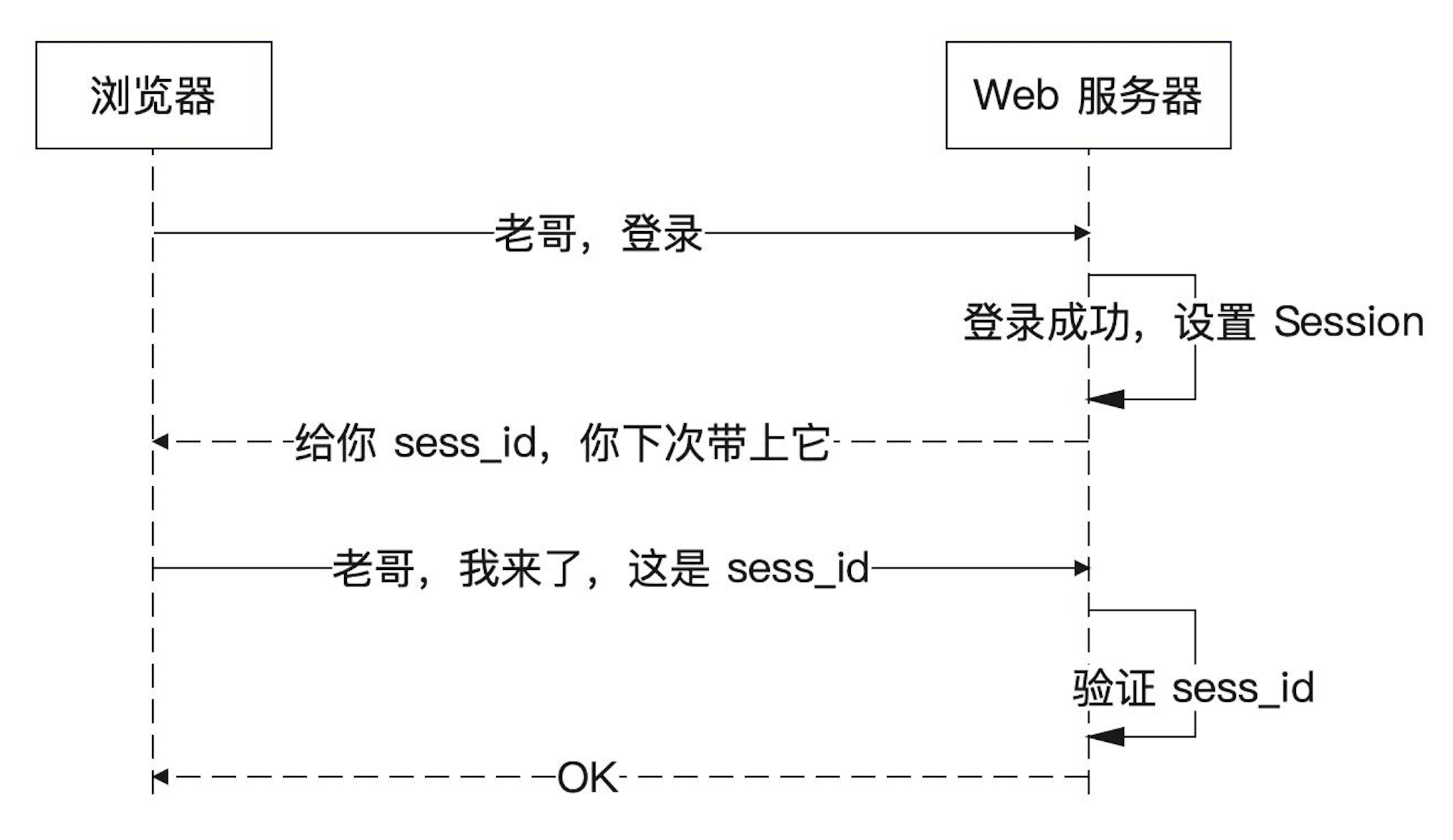
session 的关键在于服务器要给浏览器一个sess_id,也就是Session的ID。后续每一次请求都带上这个SessionID,服务端就知道你是谁了。
如果有很多人都登录了,怎么分辨哪个人对应的属于自己的 Session?session里面有个 sess_id 来表示是谁的 session,比如登录成功后会设置好 session,得到一个 sess_id,然后将 sess_id 给用户,用户下次登录的时候带上 sess_id,这样服务器就能知道是谁登录了。
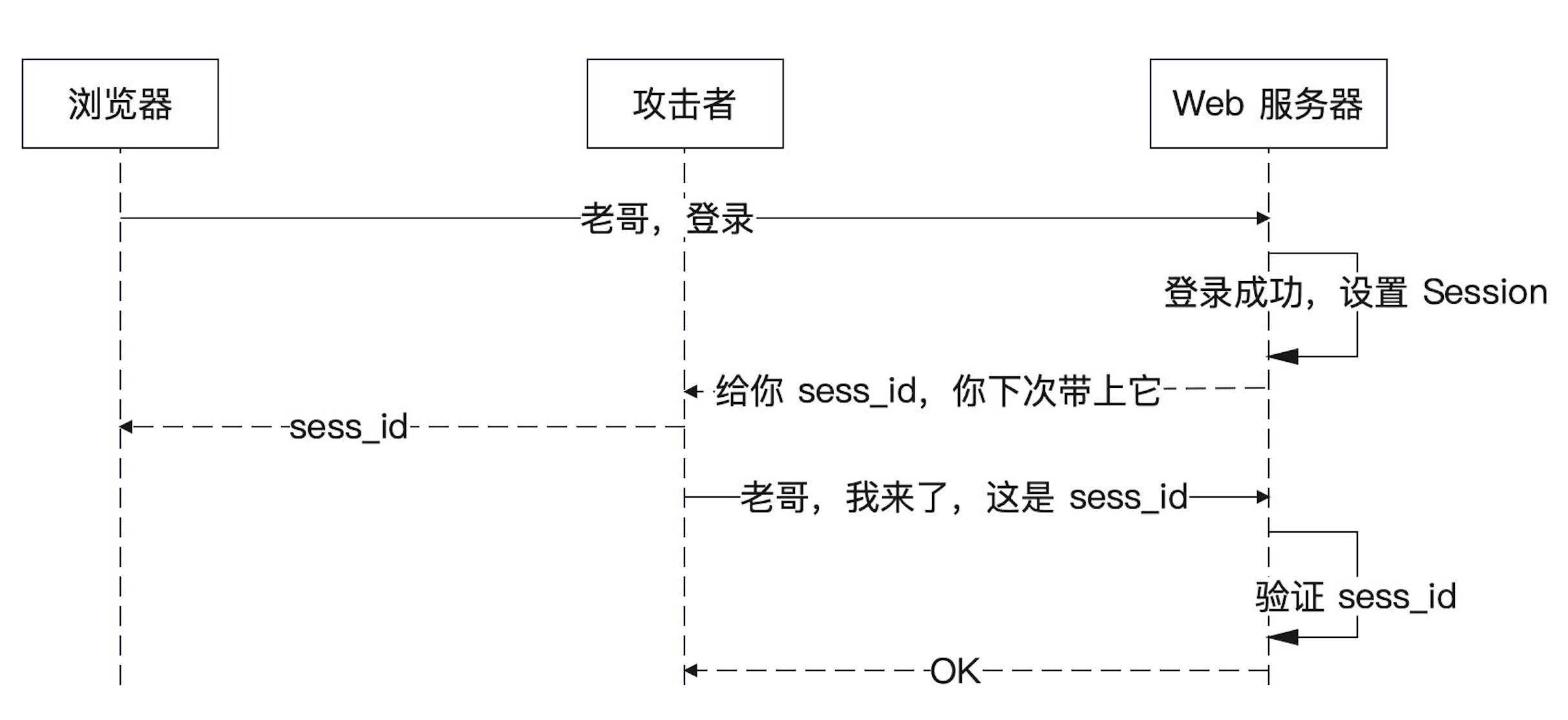
这也就意味着Session认ID不认人,后端服务器也就认ID不认人的。也就是说,如果攻击者拿到了你的ID,那么服务器就会把攻击者当成你。在下图中,攻击者窃取到了sess_id,就冒充是你了。
客户端如何携带 sess_id?
因为sess_id是标识你身份的东西,所以你需要在每一次访问系统的时候都带上。
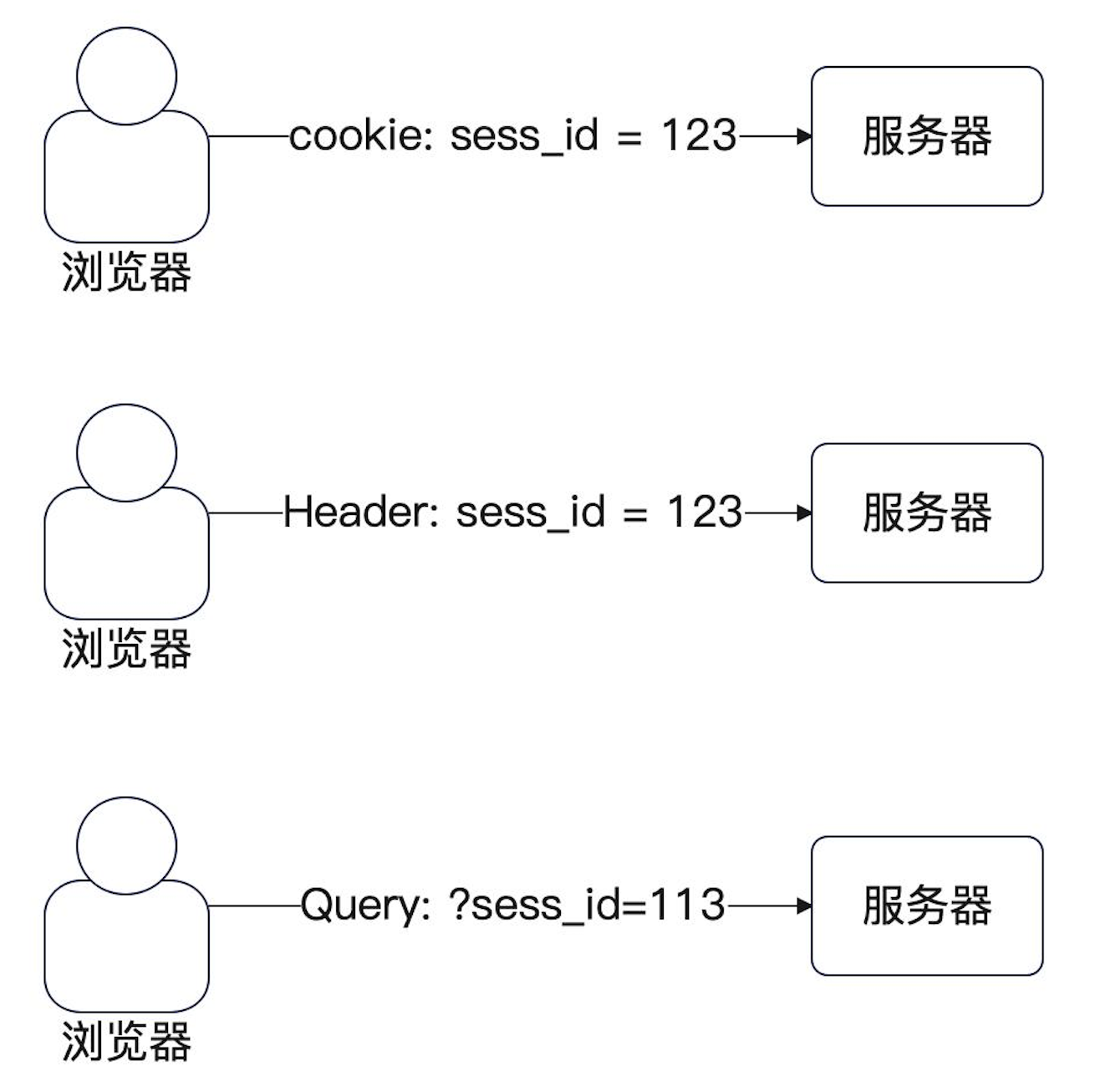
- 最佳方式就是用Cookie,也就是sess_id放到Cookie里面。sess_id自身没有任何敏感信息。
- 也可以考虑放Header,比如说在Header里面带一个sess_id。这就需要前端的研发记得在Header里面带上。
- 还可以考虑放查询参数,也就是?sess_id=xxx。
- 理论上来说还可以放body,但是基本没人这么干。在一些禁用了Cookie功能的浏览器上,只能考虑后两者。
刷新登录态
一个登录状态很经常遇到的问题,就是我们这 Session id 所在的 Cookie,过期时间是固定的。
举个例子:假如你设置为 10 分钟,那么用户登录了 9:59 秒之后,还能访问网站,结果过了两秒,他就被要求重新登录。也就是你需要在用户持续使用网站的时候,刷新过期时间。
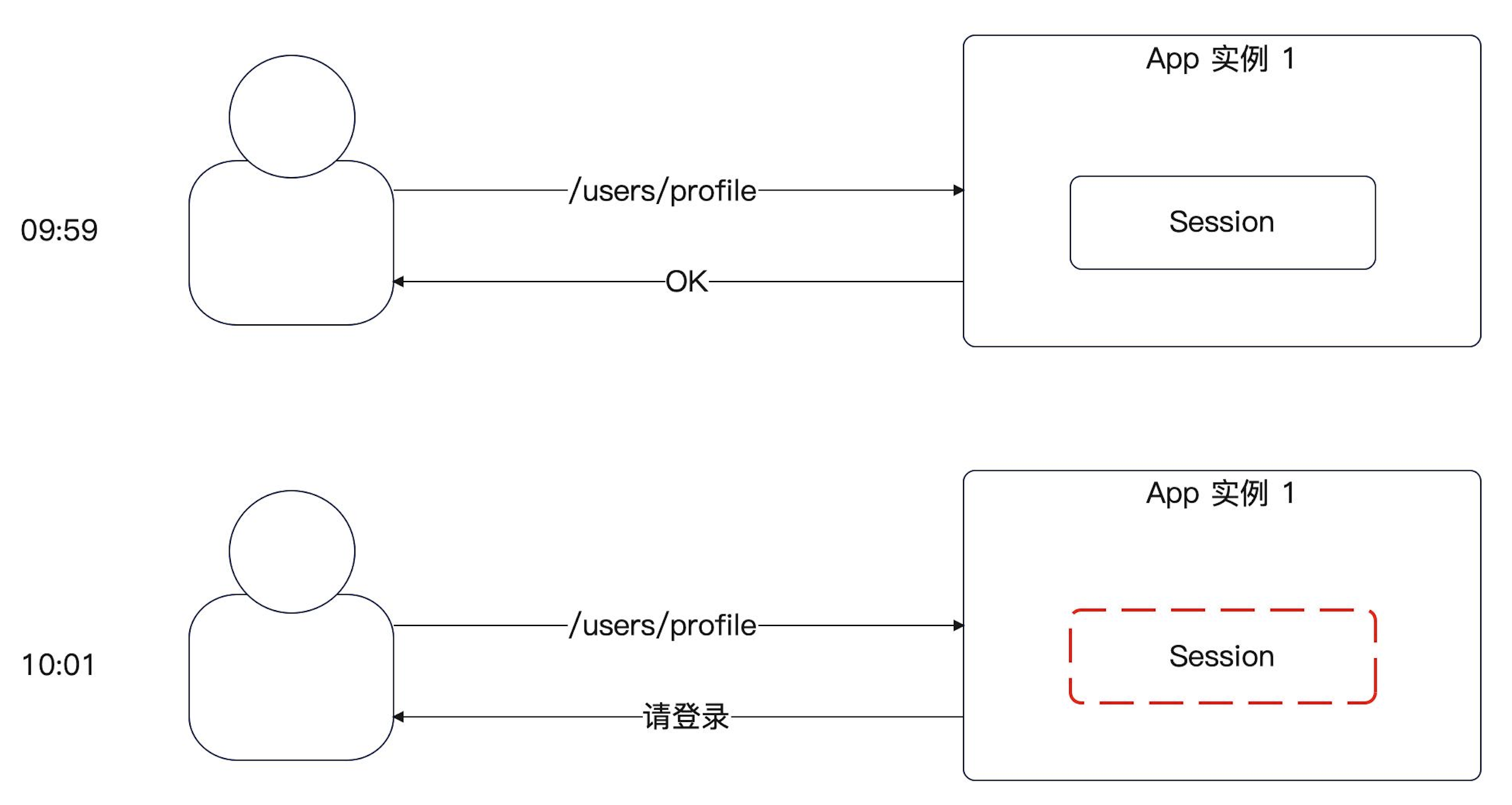
这种问题如何解决?
解决思路:
- 前端定时发送刷新请求。比如30分钟的session有效期,就设置为每隔1分钟刷新一次。
- 用户每次访问时都刷新下。缺点是性能差,对 Redis 之类的影响很大。
- 快要过期了再刷新。比如说 10 分钟过期。当用户第 9 分钟访问过来的时候,我就刷新。问题是万一在第 9 分钟以后都没人来访问过呢。
- 简单粗暴些,就固定间隔时间刷新,比如说每分钟内第一次访问我都刷新。
- 比较好的方式就是使用长短 token。有两个token,一个是长token,一个是短token,在短token过期之后,看下长token还在不在,如果在,就再生成一个短token,就相当于刷新了过期时间,如果长token也不在了呢,一般长token会设置一个星期或这个一个月,长token不在,就退出,一个星期或一个月登录一次还好,在能接受的范围内。
- 一个简单的道理,就是我们肯定不想在所有的 HTTP 接口里面都手动刷新过期时间。而刷新过期时间显然也是一个大部分业务都要完成的,因此最适合的地方肯定是在middleware 里面。于是想到,我们有一个登录校验的 middleware,显然可以在登录校验之后顺手刷新一下。
JWT
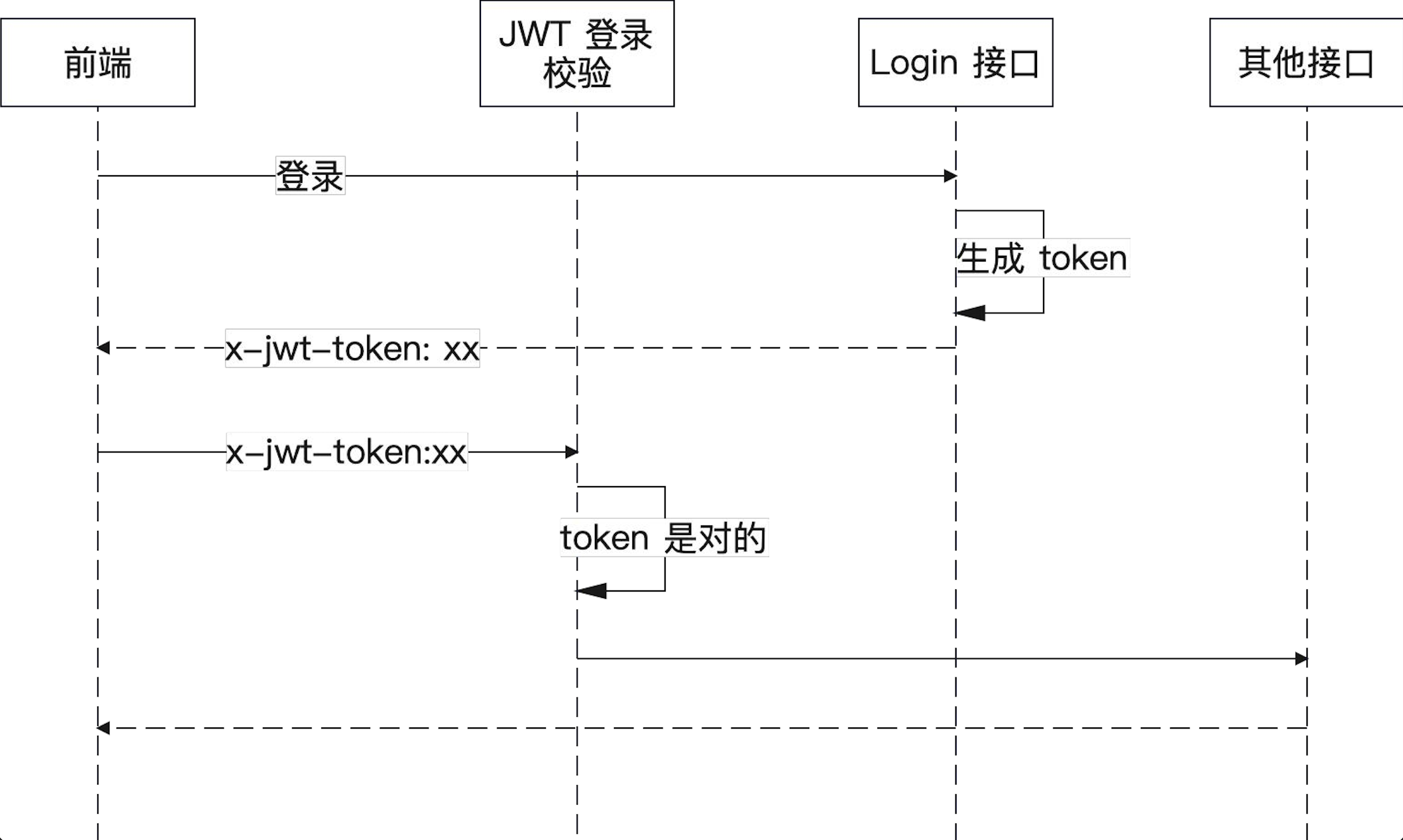
系统保护
系统的漏洞
- 任何人都可以注册
- 任何人都可以登录
如果有一个人,用 shell 脚本拼命给你发送注册请求,登录请求,系统负载就会很高。而且这两个请求都会查询数据库,也就是说数据库负载也很高。
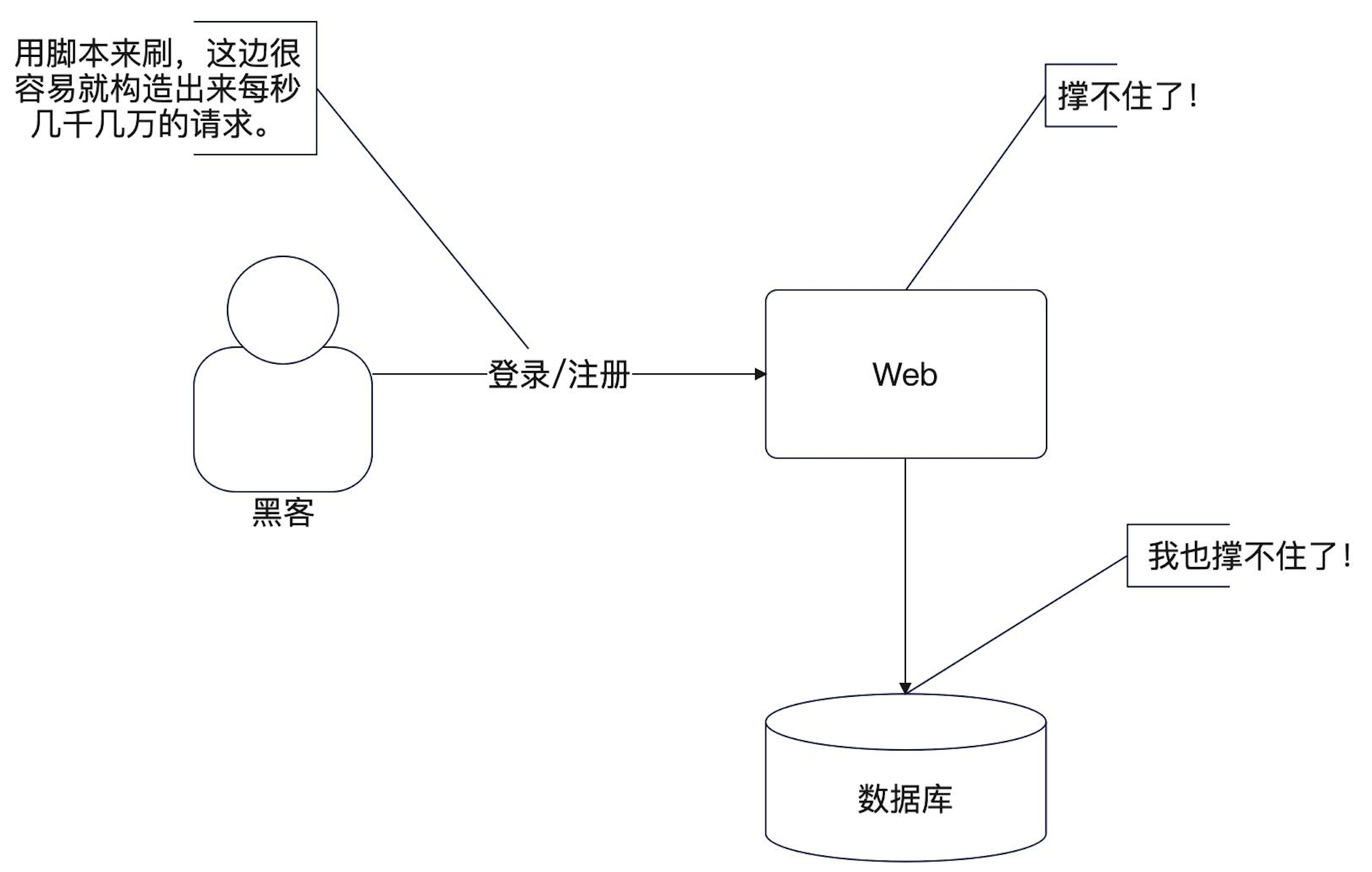
解决思路:可以考虑能不能限制每个发送的请求数量。又或者是限制住系统处理的请求数量。
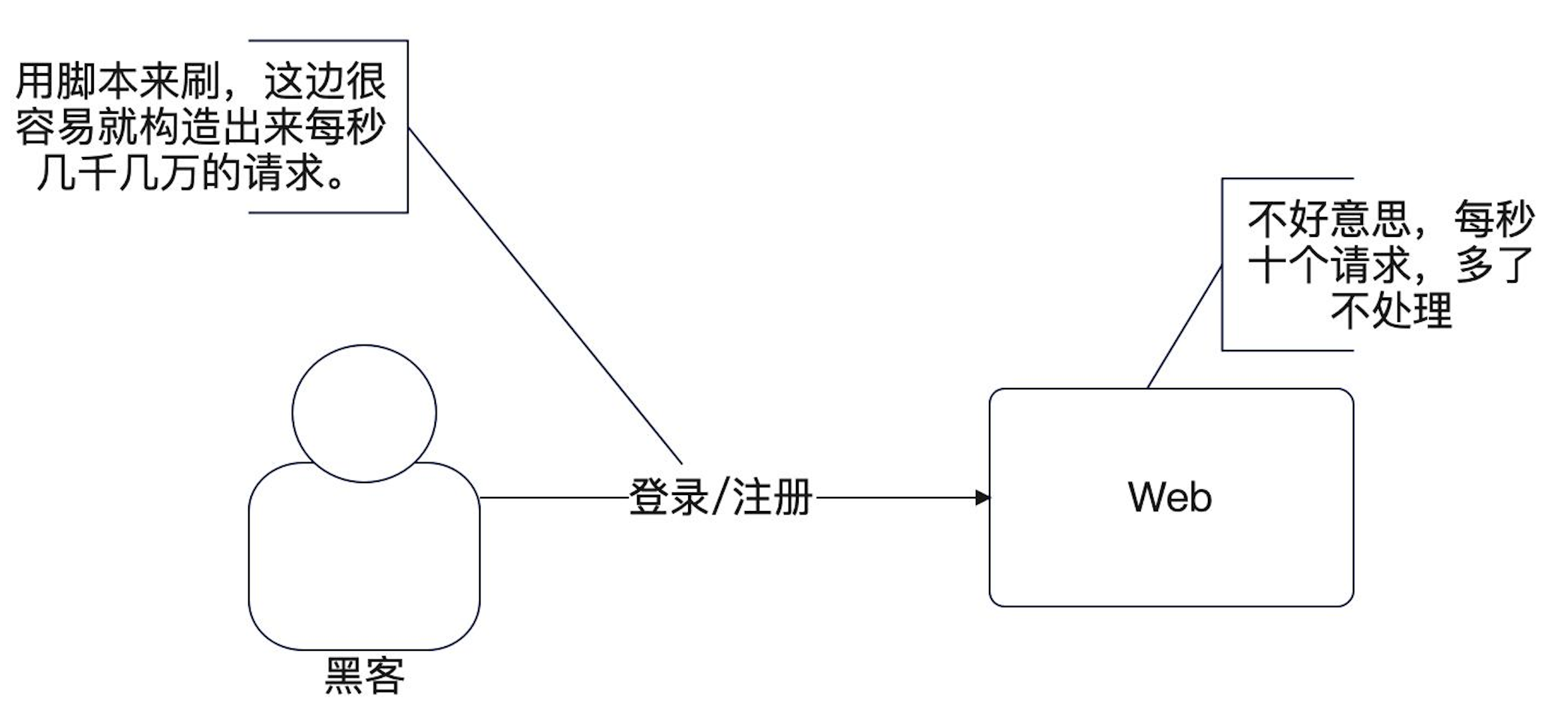
限流
限流是最常见的保护系统的办法。限流有很多算法,但是都大同小异。简单使用限流,可以限制每一个用户,每秒最多发送固定数量的请求。但这也存在也问题来:
- 我怎么认定谁是谁?尤其是在登录和注册这个接口里,都还没登录成功,我都不知道他是谁。
- 我怎么确定我限流的这个阈值应该是多少?每秒 100 还是每秒 200?
- 被限流的请求怎么办?如果每秒处理100个请求,那101个请求过来怎么办,就只能拒绝了,也就是返回错误,提示服务器繁忙,稍后再试。
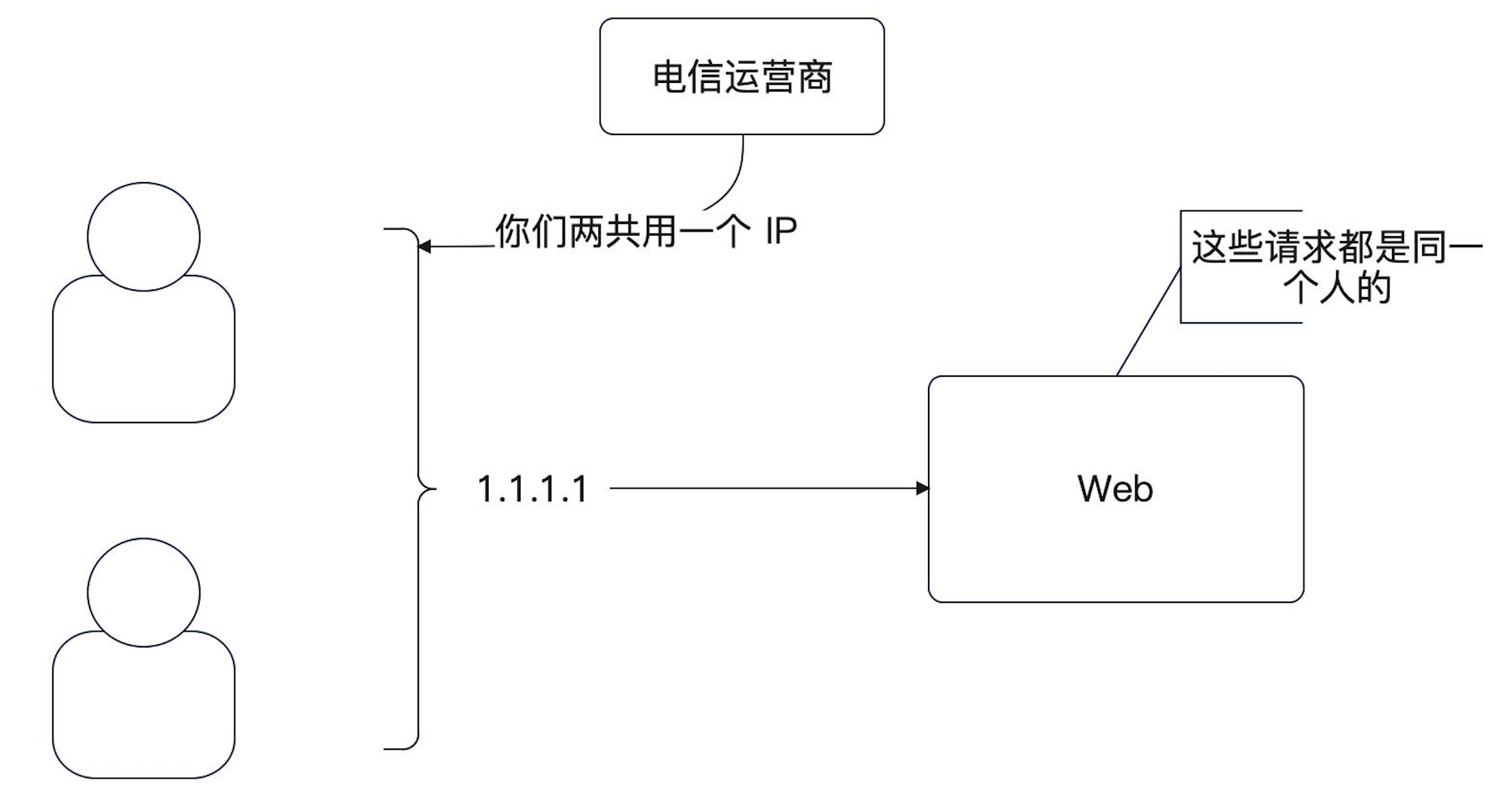
限流对象
解决思路就是使用IP,也就是我们限流针对的IP。IP虽然并不能实际代表一个人,比如一家人同时使用一个路由器,对外的IP可能就是同一个,但是是一个最简单的方案。更好的选择是Mac地址或者设备标识符之类的,比如CPU的序列号,但是在web端却很少用,APP段可以考虑使用设备序列号。
在使用IP的情况下,我们可能也会误把不同的人看成是同一个人,但是只要我们限制的阈值不是很小,一般不会有问题。
限流阈值
理论上来说,这应该是通过压测来得到的(面试回答 这个)。比如说你压测整个系统,发现最多只能撑住 每秒 1000 个请求,那么阈值就是 1000。
而我们是针对个人,搞不了压测。所以可以凭借经验
来设置,比如说我们正常人手速,一秒钟撑死一个请
求,那么就算我们考虑到共享 IP 之类的问题,给个每
秒 100 也已经足够了。
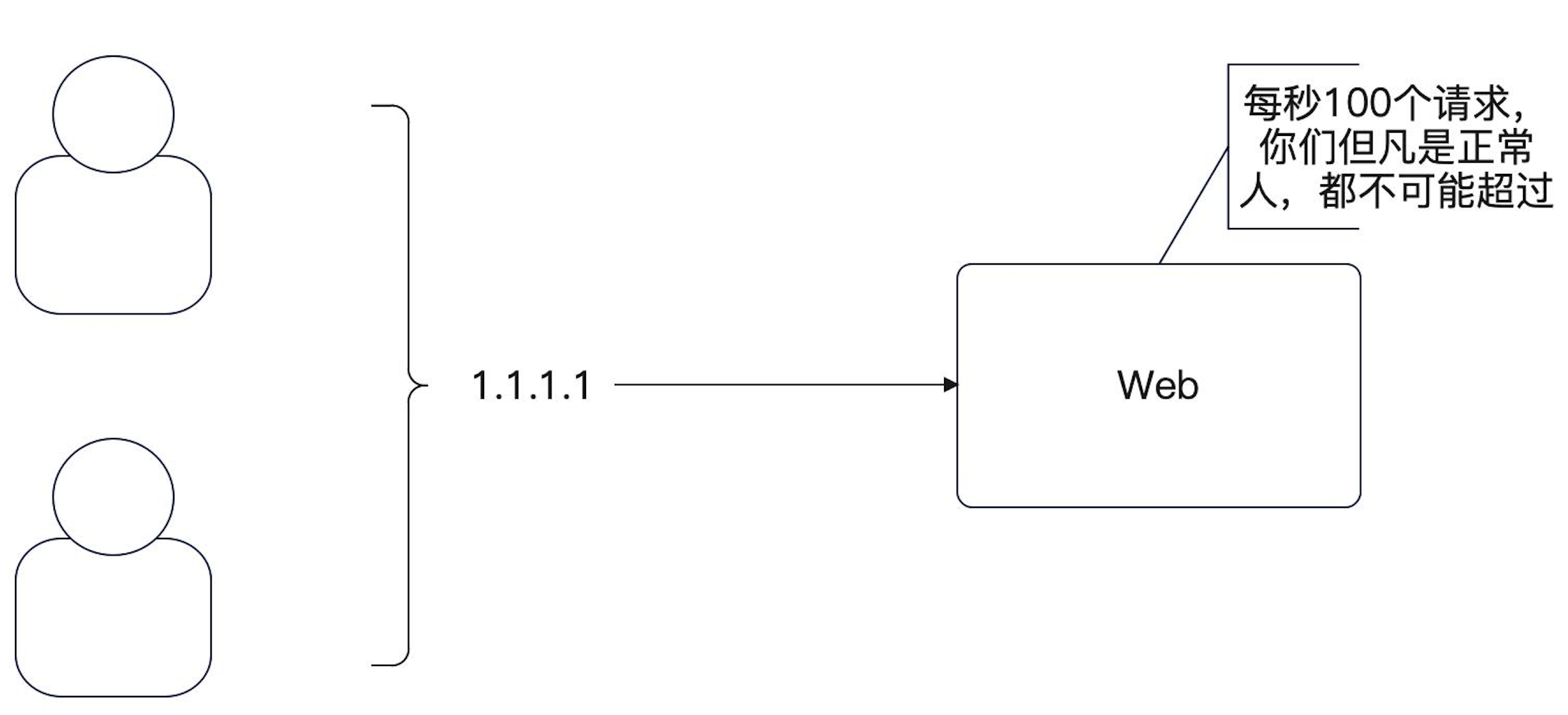
为什么使用Redis来实现限流
因为你要考虑到整个单体应用部署多个实例,用户 的请求经过负载均衡之类的东西之后,就不一定落 到同一个机器上了。 因此需要 Redis 来计数。
增强登录
有时候简单的登录功能实际上一点也不安全,不管是用 JWT 还是 Session,一旦被攻击者拿到关键的 JWT 或者 sess_id,攻击者就能假冒你。
HTTPS 可以有效阻止攻击者拿到你的 JWT 或者 sess_id。但是一旦你的电脑中了病毒,HTTP也无能为力。
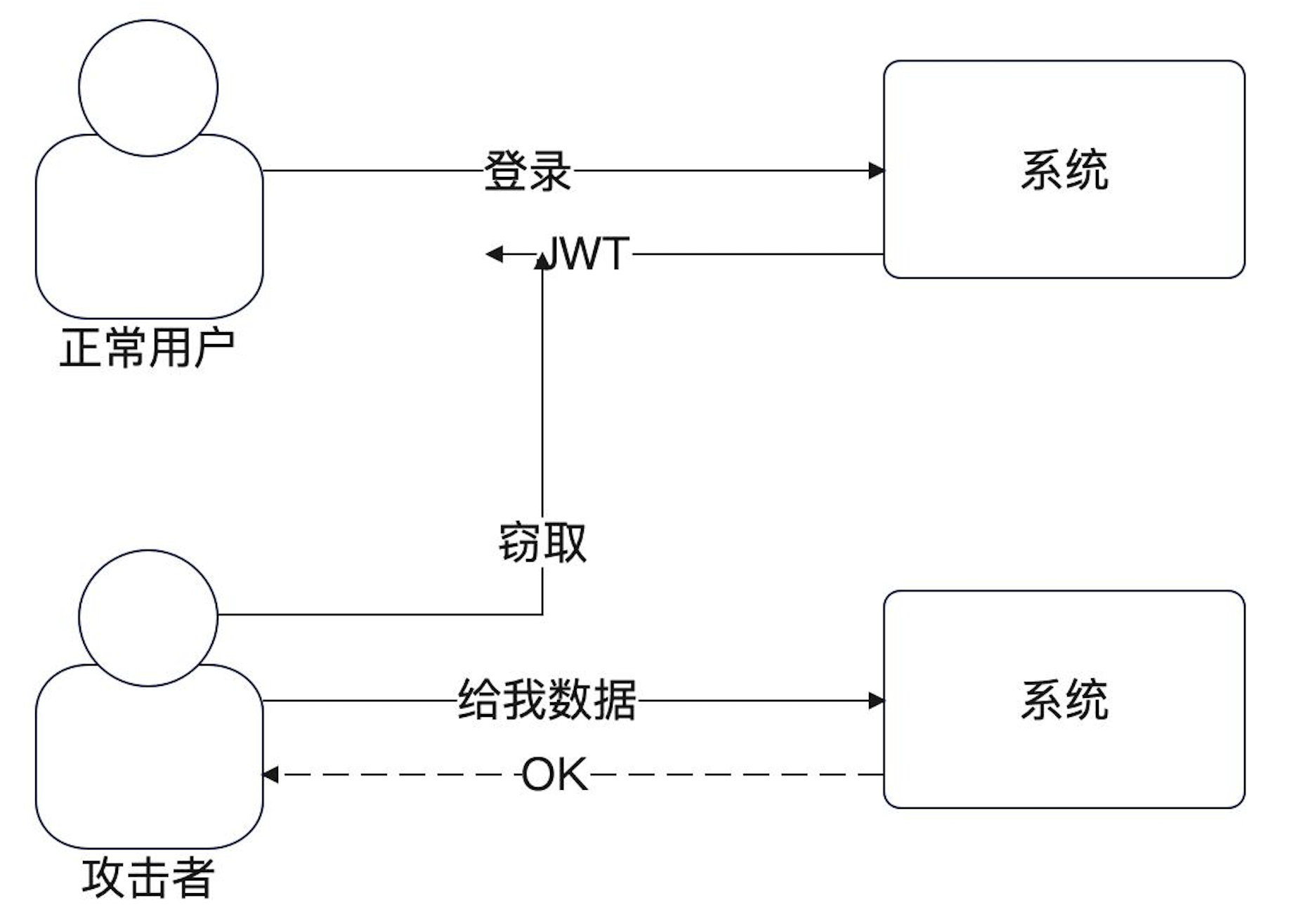
解决思路就是使用登录的辅助信息来讲登录着识别出来。比如二次验证。比如发送邮件、短信等。
在登录的嘶吼。记录一下当时登录的额外信息。比如:
- 使用浏览器时,对应到 HTTP 的 User-Agent 头部
- 硬件信息,手机APP比较常见
问题:能不能使用IP?不行,因为IP会变。
性能测试与优化
- wrk 入门
- 使用 wrk 压测已有接口 写接口测试 读接口测试
wrk 安装
|
|
压测前准备