依赖注入与Wire

文章目录
依赖注入
已有的初始化代码
|
|
仔细看我们的初始化代码,就会发现整体来说可以分成几个步骤:
- 初始化第三方依赖,也就是 DB、Redis 等。
- 用 DB、Redis 等来初始化 DAO、Cache。
- 用 DAO、Cache 初始化 Repository。
- 用 Repository 初始化 Service。
- 用 Service 初始化 Handler。
- 初始化 Gin,注册路由。
- 初始化结束。
整个过程就是层层组装,也是标准的依赖注入写法,写起来很烦,也不好重构。
所谓的依赖注入,是指 A 依赖于 B,也就是 A 要调用 B 上的方法,那么 A 在初始化的时候就要求传入 一个构建好的 B。依赖注入下,A绝对不会自己去初始化B。
对比
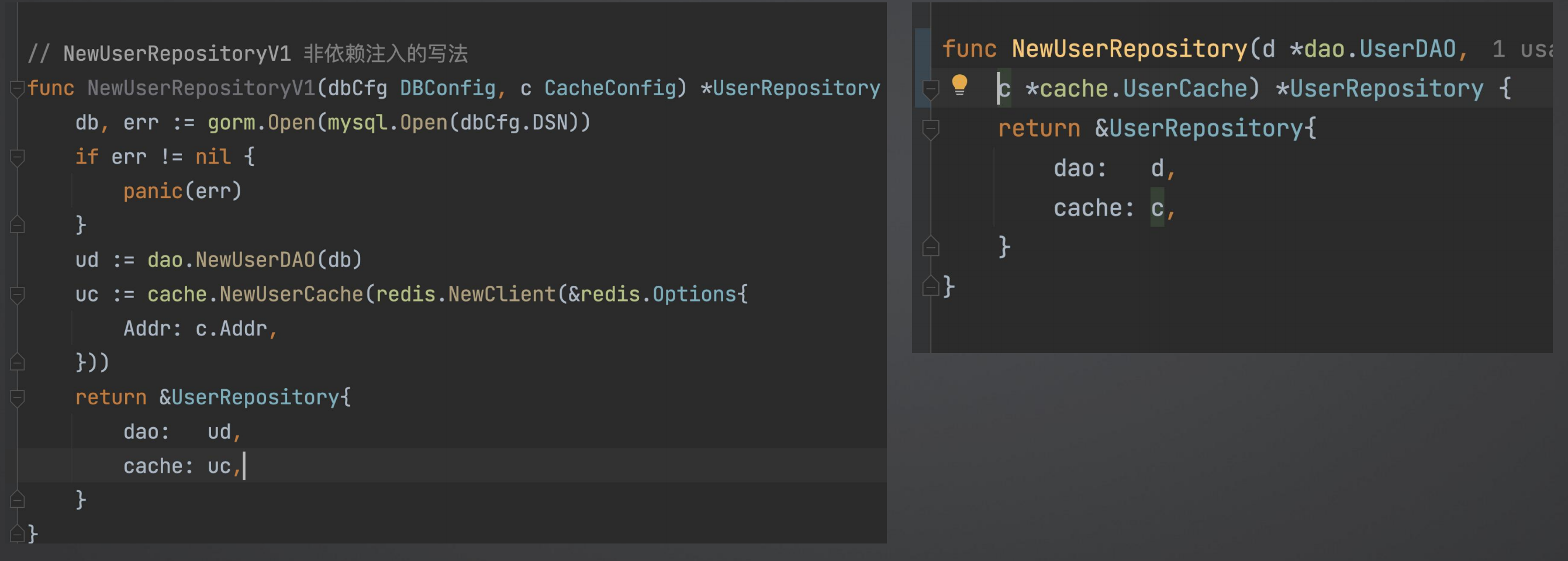
左边的写法需要方法内部自己去初始化 db, redis,然后自己去创建实例,而项目中db、redis 可能不止此处使用,还可能其他地方也会使用,这种写法就可能创建出很多的客户端。
所以这种写法的缺点需要方法自己去管理众多初始化细节,另外不方便复用像db|redis这些公共资源,重复创建需要客户端。
后边的写法,方法内部需要使用什么,直接由外部传进来。自己根本不关心被使用对象的初始化细节。
就像小时候我根本不管父母怎么挣钱的,我只管花。 就像老板向助手要一个会议的PPT,他根本不管PPT怎么做的,只关心助手为他的演讲提供一个PPT,PPT上有他要将的主题内容。
依赖注入写法:不关心依赖是如何构造的。 非依赖注入写法:必须自己初始化依赖,比如说 Repository 需要知道如何初始化 DAO 和 Cache。由此带来的缺点是:
- 深度耦合依赖的初始化过程。
- 往往需要定义额外的 Config 类型来传递依赖所需的配置信息。
- 一旦依赖增加新的配置,或者更改了初始化过程,都要跟着修改。
- 缺乏扩展性。
- 测试不友好。
- 难以复用公共组件,例如 DB 或 Redis 之类的客户端。
引入依赖注入中间件
依赖注入的缺点就是要在系统初始化的过程中(main函数),完成复杂冗长的构造链表。 所以我们可以借助一些中间件来帮助我们完成这些复杂又没有多少技术含量的事情。
在 Go 里面,我推荐使用 wire。 wire 分成两部分,一个是在项目中使用的依赖,一个是命令行工具。
安装:
|
|
确保 GOPATH/bin 在你的环境变量 PATH 里面,不然就是 command not found。
wire
wire 简单示例
wire 使用有两个基本步骤:
- 往 wire 里面注册各种初始化方法。
- 运行 wire 命令。
第一步相当于告诉 wire,我有什么东西,每个东西是怎么初始化的。 第二就是让 wire 完成组装。
wire 生成代码
可以看到, wire 是利用了代码生成技术。它会根据你传入的各种构造方法,分析其中的依 赖,然后生成一个真正的初始化方法。
注意,wire 本身并不支持单例模式,因此,假如你多次调用 InitDB,那么就会生成多个 gorm.DB。后面我们会解决这个问题。
IoC:控制反转
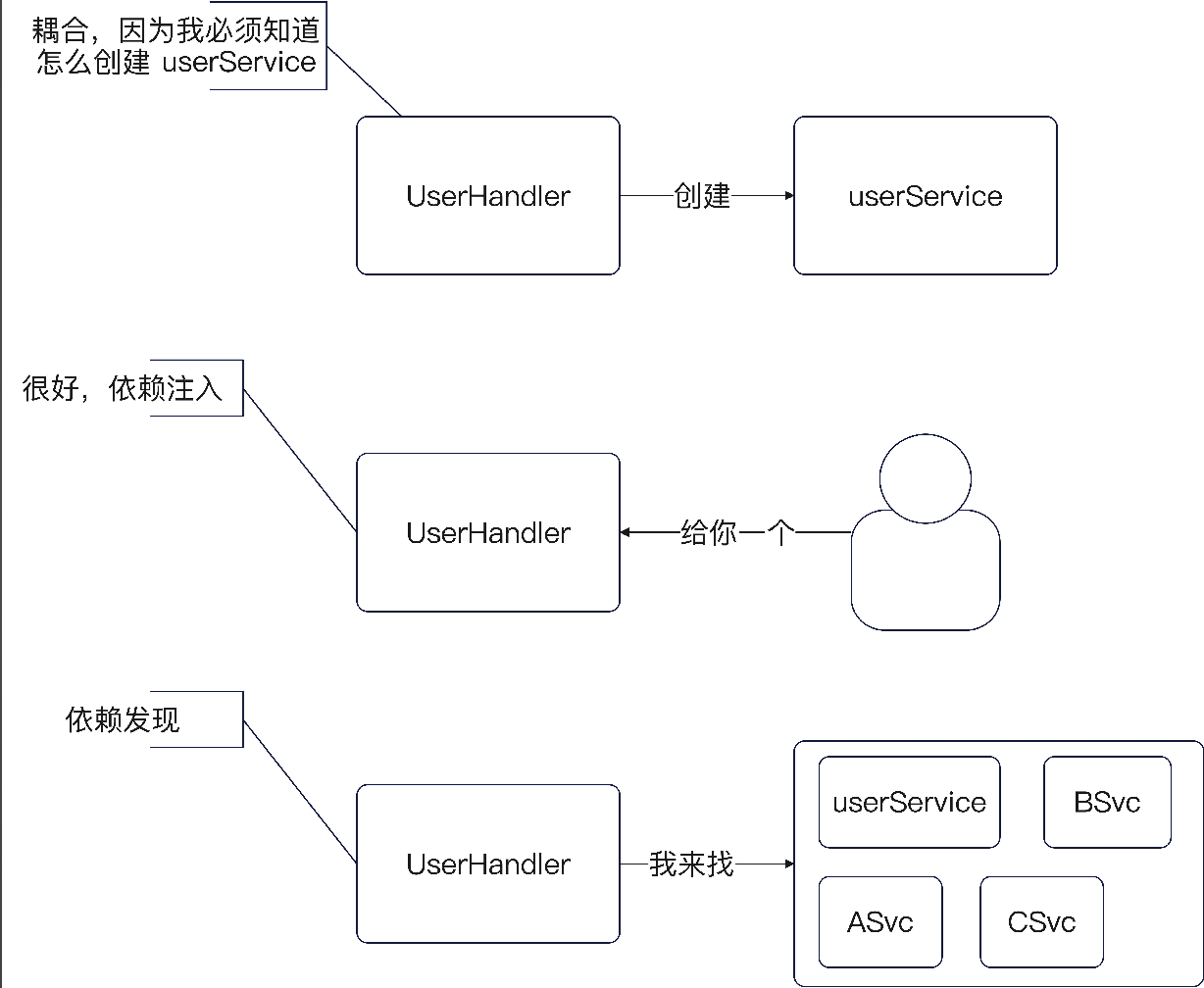
依赖注入是控制反转的一种实现形式。
还有一种叫做依赖发现。比如说 A 调用 B,然后 A 自己去找到可用的 B,那就是依赖发现。
简单来说,如果 A 用 B 接口的时候,需要自己创建一个,比如说 UserHandler 里面自己创建一个 UserService 的实现,那么 UserHandler 就和 UserService 的实现耦合在一起了。
控制反转的意思就是,UserHandler 不会去初始化UserService。要么外面传入 UserService 给UserHandler,这种叫做依赖注入;要么是 UserHandler自己去找一个 UserService,这种叫做依赖查找。
组装过程
整个过程可以看下图。关键点:
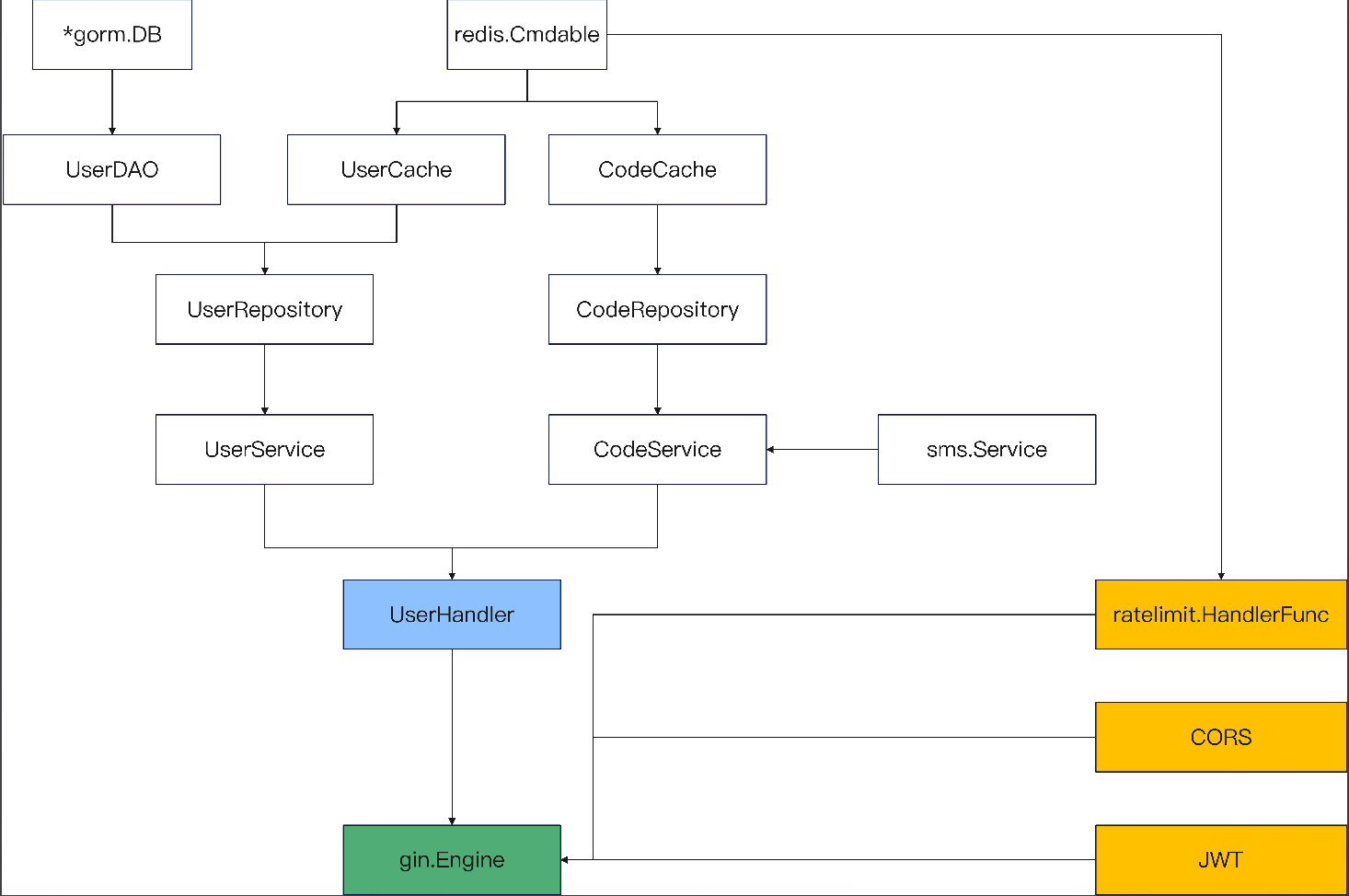
- DAO、Repository、Service 和 Handler 都已经有构造方法了。
- 需要有一个新的方法,用于准备接入的 Gin HandlerFunc。
- 需要有一个新的方法,初始化对应的 sms.Service。
- 需要有一个新的方法,集成所有的 Handler、Gin HandlerFunc,完成路由注册。
而后在 main 函数里面直接启动就可以。