Redis初识

文章目录
Redis是什么
- 开源。
- 高性能
Key-Value键值对存储服务系统,可理解为一个数据库,QPS可达10万级别。 - 支持多种数据结构。
- 支持高可用、分布式。
- 提供了丰富的功能,如 pipline、慢查询、发布订阅等。
Redis特性
- 速度快
- 支持持久化
- 支持多种数据结构
- 支持多种编程语言
- 功能丰富
- 简单,代码短小精悍,另外使用也简单
- 支持主从复制,可以将主节点数据作为一个副本
- 高可用、分布式,主从复制是高可用、分布式的基础
速度快
官方给出的数据可达到10w OPS,也就是每秒可实现10w次读写,但也要分场景,但从实际使用中,达到万级别是没有问题的。
为什么会这么快?
- 首先 Redis 是将数据存在内存中的,我们知道服务器的内存读取是非常快的。
- 其次它是使用C语言实现的,C语言是离操作系统较近的语言,代码短小精悍。
- 基于单线程模型,平时我们写代码都知道单线程是很慢的,所以有些场景会使用多线程来解决问题,redis使用单线程主要是因为内存读写速度很快,使用单线程基本就可以达到很高的性能,但很多实际开发中多线程会成为并发的瓶颈。
速度快主要原因还是因为内存。


持久化(断电不丢数据)
Redis 的数据都是保存在内存中的,我们都知道内存中的数据不具有持久化特性,也就是说当我们机器发生断电的时候,是无法对内存数据进行恢复的,Redis也想到了这一点,所以提供了持久化的功能。 也就是说Redis所有数据保存在内存中,对数据的更新将异步地保存到磁盘上。因为硬盘是有持久特性的。
支持多种数据结构
提供了5种数据结构,包括字符串,哈希,列表,集合,有序集合。

还提供了 BitMaps 位图,HyperLogLog 超小内存唯一值计数,GEO 地理信息定位等数据结构。
功能丰富
- 支持发布订阅
- Lua脚本
- 事务
- pipline
简单
- 不依赖外部库 like libevent
- 单线程模型
主从复制

主服务器数据可以同步到从服务器上,这样可以为高可用和分布式提供一个很好的基础。
高可用、分布式
- 高可用:Redis-Sentinel(v2.8)支持高可用
- 分布式:Redis-Cluster(v3.0)支持分布式
使用场景
- 缓存系统
- 计数器
- 消息队列系统
- 排行榜
- 社交网络
- 实时系统
缓存系统


- 用户访问一个 App Server。
- 首先会先从 cache 中查询,主要是为了提高响应速度,因为cache通常是存放于内存中,读写速度较快,如果 cache 中有就直接返回给 AppServer。
- 如果 cache 中没有,就会去 Storage 中去取数据;为了下一次在 cache 中获取到相同的数据,会在 Storage 中的数据存放到 cache 中;最后将 Storage 中的数据返回给用户,当用户下次访问的时候就可以从 Cache 中获取。
数据结构与内部编码
目的是为了Redis内存优化

redis 的每个数据结构都有自己的内部编码,比如hash,对于用户而言,它的type是 hash, 实际上在内部,可能使用 hashtable 或者 ziplist 压缩列表
为什么这样做,首先 redis 是个内存的数据库,如果在使用一种数据结构的时候,以空间换取时间就可以使用一些压缩的结构,就像hash 里面有 ziplist 这样的结构,当它的元素个数比较小的时候,就可以用空间来换时间,因为元素个数比较小,元素的一些操作或者遍历或者查找也不会消耗很多时间或者CPU,这样就可以使用一个更小的空间来达到更优的内存使用效果,对于其他4中数据结构也是类似原理
在 redis 内部有个 redisObject 的对象或者说一个结构体,它有很多属性。 其中一个是数据类型 type,就是对外的数据结构类型,如 string, hash, list, set, sorted set 还有一个是编码方式 encoding, 比如raw, int, ziplist, linkedlist, hashmap, intset 还有其他属性,比如数据指针ptr, 虚拟内存vm, 其他信息
单线程架构

比如现在有个redis 服务,每个执行的命令相当于进入了一条高速公路,这个高速公路只有一条车道,也就是说不能两条命令同时执行,比如执行一个get命令的时候后面命令必须等待,等第一个 get 执行了之后,才能执行第二个 get,然后第三个 del,相当于一个串行的结果,这个其实就是redis单线程最简单的表现
记住一句话:redis 在一瞬间只能执行一条命令,不会同时执行两条命令
单线程为什么这么快?
在开发的时候一般单线程都是比较慢的,通常会使用多线程,那为什么redis使用单线程可以达到很快的效果呢?
1、纯内存
redis会将所有数据存放于内存中,内存的响应速度是非常快的,响应时间大概是100纳秒,也就是说 我们常说的redis高性能,其实是依赖内存的,另外代码也做了很多优化,但实际上本质是把数据放在内存中的。
2、非阻塞IO
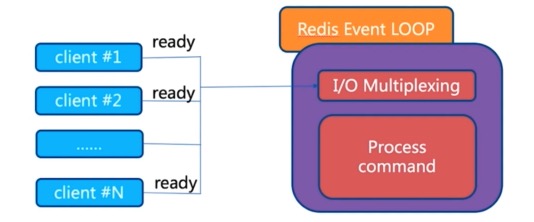
就是 redis 使用了像 epoll 这样的模型作为 I/O 多路复用的实现,另外Redis自身实现了事件处理,将 epoll 连接读写关闭转为自身的事件,不在I/O上浪费过多的时间,这个也是它非常快的原因。
3、避免线程切换和竞态消耗
很多时候使用多线程,没有得到合理使用的时候,甚至比单线程还要慢。




一瞬间只能执行一条命令,而且使用 epoll 的非阻塞IO进行消费
使用单线程需要注意什么?
1、一次只运行一条命令
因为使用内存,一条命令在内存中的响应时间大概是100纳秒,也就非常快
2、拒绝长(慢)命令
长命令有: keys, flushall, flushdb, slow lua script, multil/exec, operate big value(collection) 等 这些命令不要在线上执行,比如一个 keys 因为数据很多,执行了10s,因为redis单线程的,这个命令没有执行完,后面的命令就会阻塞住,就需要等待前面的命令执行完才能去执行
Redis作为一个高性能的产品来说,一个应用想要达到 1 秒执行1万次命令,如果卡住了20s,所有的命令都会卡住,就会对应用预想的结果肯定不一样,还有可能达到超时,对于高可用的场景也是非常危险的。