通用命令
- keys: 统计Redis中的所有键
- dbsize: 统计数据库大小,比如有10个key,dbsize就是10
- exist key: 判断key是否存在,key可以是任意数据类型
- del key [key …]: 删除key,可以删除多个key
- expire key seconds: 为 key 设置过期时间,一段时间后 key 会自动删除
- type key: 查看 key 数据类型,比如是字符串类型还是哈希类型
keys *
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> set php good
OK
127.0.0.1:6379> set java best
OK
127.0.0.1:6379> keys *
1) "hello"
2) "java"
3) "php"
127.0.0.1:6379> dbsize
(integer) 3
127.0.0.1:6379>
|
keys [pattern]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
127.0.0.1:6379> mset hello world hehe haha php good phe his
OK
127.0.0.1:6379> keys *
1) "hello"
2) "hehe"
3) "java"
4) "php"
5) "phe"
127.0.0.1:6379> keys he*
1) "hello"
2) "hehe"
127.0.0.1:6379> keys he[h-l]*
1) "hello"
2) "hehe"
127.0.0.1:6379> keys ph?
1) "php"
2) "phe"
127.0.0.1:6379>
|
keys 命令使用注意
keys 很好用,但是 keys 命令一般不在生产环境使用,因为生产环境中键值对一般比较多,keys 命令是比较重的命令,时间复杂度为 O(n) 。比如有100w个 key-value,一次执行会比较慢。还有因为Redis是单线程命令,所以会阻塞其他命令,另外取出这些范围的数据也没什么意义。
如果真有要扫描所有的key的需求,比如将长期不用的 Key 输出出来,来提高内存的使用率,这种场景怎么使用呢?
除了使用 scan 命令以外还可以使用 热备从节点。主从复制 也就是从节点可以复制主节点的数据,可以认为主节点有什么数据,从节点也有什么数据,主节点加了什么数据,从节点就会立刻有什么样的数据,一般来说从节点不会给生产环境使用,就可以在从节点上执行一些比较重的命令,也就不会造成生产级别的危害。
dbsize
1
2
3
4
5
6
7
8
9
|
127.0.0.1:6379> mset k1 v1 k2 v2 k3 v3 k4 v4
OK
127.0.0.1:6379> dbsize
(integer) 4
127.0.0.1:6379> sadd myset a b c d e
(integer) 5
127.0.0.1:6379> dbsize
(integer) 5
127.0.0.1:6379>
|
dbsize 是可以在线上使用的,可能有人会认为 dbsize 会计算所有的键值总数,会把键值字典或者什么全局的表遍历一遍,实际上不是这样的,而是Redis内置了一个这样的计数器,会实时更新数据库的key的总数,所以说 dbsize 可以在线上随便使用,它的时间复杂度是 O(1)
exists key
- 检查 key 是否存在,存在返回 1,不存在返回 0
1
2
3
4
5
6
7
8
9
|
127.0.0.1:6379> set a b
OK
127.0.0.1:6379> exists a
(integer) 1
127.0.0.1:6379> del a
(integer) 1
127.0.0.1:6379> exists a
(integer) 0
127.0.0.1:6379>
|
exists 命令也是 O(1) 级别的,可以在线上使用。
del key
- 删除指定的 key-value,也可以删除多个,成功删除返回 1,如果key 压根就不存在返回 0
1
2
3
4
5
6
7
8
9
|
127.0.0.1:6379> set a b
OK
127.0.0.1:6379> get a
"b"
127.0.0.1:6379> del a
(integer) 1
127.0.0.1:6379> get a
(nil)
127.0.0.1:6379>
|
expire key seconds
- key 在 seconds 秒后过期,另外还可以设置在某个时间戳过期,还可以设置在多少毫秒内过期,也可以设置在多少毫秒的时间戳过期
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> expire hello 20
(integer) 1
127.0.0.1:6379> ttl hello
(integer) 17
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> ttl hello
(integer) 1
127.0.0.1:6379> ttl hello
(integer) -2
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379>
|
-2 表示这个 key 已经不存在了,已经超过了20s,在 expire 内部会将它执行 del 命令过期删除
ttl key
persist key
1
2
3
4
5
6
7
8
9
10
11
12
13
|
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> expire hello 20
(integer) 1
127.0.0.1:6379> ttl hello
(integer) 17
127.0.0.1:6379> persist hello
(integer) 1
127.0.0.1:6379> ttl hello
(integer) -1
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379>
|
-1 表示 key 存在,并且没有过期时间
type key
返回key的类型,类型有 string, hash, list, set, zset, none,none 表示在一个不存在的 key上执行type命令
1
2
3
4
5
6
7
8
9
|
127.0.0.1:6379> set a b
OK
127.0.0.1:6379> type a
string
127.0.0.1:6379> sadd myset 1 2 3
(integer) 3
127.0.0.1:6379> type myset
set
127.0.0.1:6379>
|
时间复杂度
| 命令 |
时间复杂度 |
| keys |
O(n) |
| dbsize |
O(1) |
| del |
O(1) |
| exists |
O(1) |
| expire |
O(1) |
| type |
O(1) |
字符串类型
键值结构
redis 所有的 key 都是字符串,无论什么类型,value 是就是常见的5种类型。value 可以是字符串、数字、二进制、json等。
| key |
value |
| hello |
world |
| counter |
1 |
| bits |
10111101 |
| json |
{“product”: {“id”: “10000”, “name”: “jack”}} |
注意
字符串的 value 不能大于 512MB。这个限制其实足够大了,如果真的要存一个值几百MB,首先在取的时候会消耗网络流量,其次读取的时候也非常慢,因为它有一定的网络开销,这个对于单线程来说也不是特别好,所以一般建议 key-value 在100KB以内。
使用场景
命令
get key:获取 key 对应的 value,时间复杂度O(1)。
set key value:设置 key 对应的 value,时间复杂度O(1)。不管key是否存在都会设置,当重复设置时,后值会覆盖前值。
del key:删除指定 key-value,时间复杂度O(1)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# 首先判断 key 是否存在
127.0.0.1:6379> get hello
(nil)
# 对不存在的 key 设置
127.0.0.1:6379> set hello world
OK
# 获取
127.0.0.1:6379> get hello
"world"
# 再对已存在key进行设置
127.0.0.1:6379> set hello redis
OK
# 获取,发现原值已被覆盖
127.0.0.1:6379> get hello
"redis"
# 删除
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379>
|
incr key:计数,key对应的value自增1,如果key不存在,value初始值为0,自增后get(key)=1,时间复杂度O(1)。
decr key:计数,key对应的value自减1,如果key不存在,value初始值为0,自减后get(key)=-1,时间复杂度O(1)。
incrby key k:计数,key对应的value自增k,如果key不存在,自增后get(key)=k,时间复杂度O(1)。
decrby key k:计数,key对应的value自减k,如果key不存在,自减后get(key)=-k,时间复杂度O(1)。
注意:如果值包含错误的类型,或字符串类型的值不能表示为数字,那么返回一个错误。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
# 获取一个不存在的 key
127.0.0.1:6379> get counter
(nil)
# 自增
127.0.0.1:6379> incr counter
(integer) 1
127.0.0.1:6379> get counter
"1"
# 指定增量自增
127.0.0.1:6379> incrby counter 99
(integer) 100
# 自减
127.0.0.1:6379> decr counter
(integer) 99
# 指定增量自减
127.0.0.1:6379> decrby counter 99
(integer) 0
127.0.0.1:6379> get counter
"0"
# 设置一个错误的类型
127.0.0.1:6379> set hello world
OK
# 返回一个错误
127.0.0.1:6379> incr hello
(error) ERR value is not an integer or out of range
|
使用场景
- 记录网站每个用户的个人主页访问量,比如 incr userid:pageview
- 缓存视频基本信息,原始信息保存于 MySQL 中,为提供访问效率或并发量,将缓存信息保存于Redis中
- 分布式ID生成器,多实例部署时通过Redis的原子单线程特点来获取一个自增的ID
setnx key value:SET if Not eXists。当key不存在时才设置value,可以理解成添加操作。当key已存在时,虽然设置失败无报错(返回0)。时间复杂度O(1)。
set key value xx:当key存在,才设置,可以理解成更新操作,时间复杂度O(1)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
# 设置一个不存在key
127.0.0.1:6379> exists golang
(integer) 0
127.0.0.1:6379> set golang good
OK
# 设置一个已存在的key,返回0表示未设置成功
127.0.0.1:6379> setnx golang bad
(integer) 0
# 更新一个已存在的key的value值
127.0.0.1:6379> set golang best xx
OK
127.0.0.1:6379> get golang
"best"
127.0.0.1:6379> exists php
(integer) 0
# 设置一个不存在的key的value
127.0.0.1:6379> setnx php best
(integer) 1
# 更新一个已存在的key的value
127.0.0.1:6379> set php easy xx
OK
127.0.0.1:6379> get php
"easy"
127.0.0.1:6379> exists java
(integer) 0
# 更新一个不存在的key的值,更新失败
127.0.0.1:6379> set java hehe xx
(nil)
127.0.0.1:6379>
|
mget key1 [key2…]:批量获取key,原子操作,时间复杂度O(n)。
mset key1 value1 key2 value2 key3 value3:批量设置key-value,时间复杂度O(n)。
1
2
3
4
5
6
7
|
127.0.0.1:6379> mset hello world golang best php good
OK
127.0.0.1:6379> mget hello golang php
1) "world"
2) "best"
3) "good"
127.0.0.1:6379>
|
n次get 与 1次mget
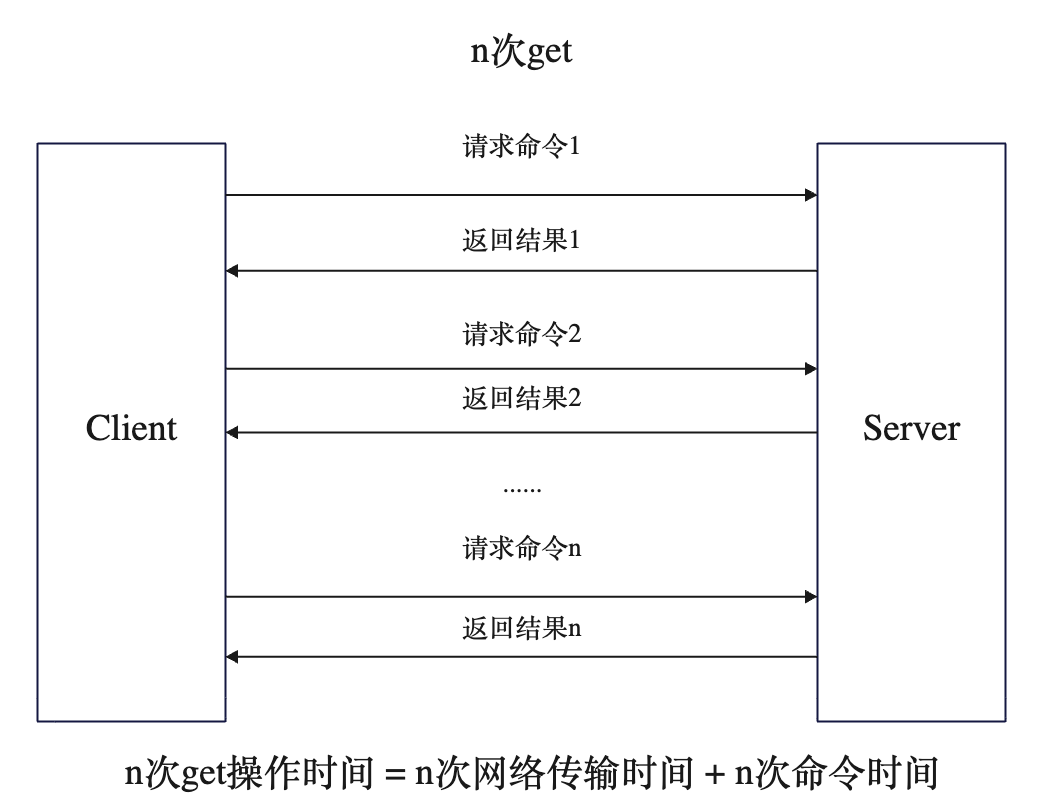
需要执行n次get操作才能达到mget效果。其中最主要的是网络时间,我们的客户端和服务端一般都是不同的机器,它们在不同的机房甚至不同的地区,所以网络时间是个很大的开销,而命令时间本身开销很小,因为redis的执行速度非常快。
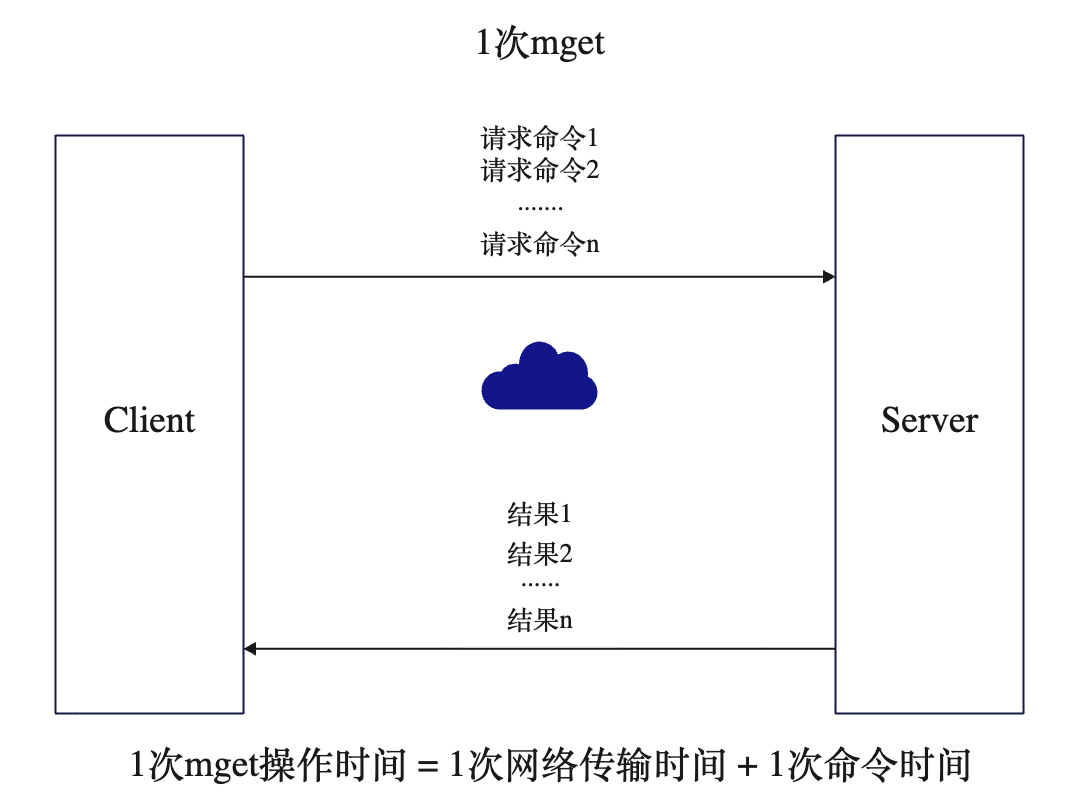
一次mget = 1次网络时间 + n次命令时间
所以像 mget 操作就可以省去大量的网络时间,我们可以将一批命令批量的传给服务端,服务端会通过网络一次性将结果返回给我们,很多情况下这种方式效率是很高的。
但是需要注意 mget key的数量不是无限的。
getset key newvalue:为key 设置新值并返回旧的value,时间复杂度O(1)。
append key value:将 value 追加到旧的value,时间复杂度O(1)。
strlen key:返回字符串的长度(注意中文),时间复杂度O(1)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> getset hello redis
"world"
127.0.0.1:6379> append hello ", mysql"
(integer) 12
127.0.0.1:6379> get hello
"redis, mysql"
127.0.0.1:6379> strlen hello
(integer) 12
127.0.0.1:6379> set china "中国"
OK
127.0.0.1:6379> strlen china
(integer) 6
127.0.0.1:6379>
|
incrbyfloat key 3.4:增加key对应的值3.4,没有自减命令,但是可以提供一个负数来达到递减效果,时间复杂度O(1)。
getrange key start end:获取字符串指定下标所有的值,时间复杂度O(1)。
setrange key index value:设置执行下标所有对应的的值,时间复杂度O(1)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
127.0.0.1:6379> incr counter
(integer) 1
127.0.0.1:6379> incrbyfloat counter 1.1
"2.1"
127.0.0.1:6379> get counter
"2.1"
127.0.0.1:6379> set hello javabest
OK
127.0.0.1:6379> getrange hello 0 2
"jav"
127.0.0.1:6379> setrange hello 4 p
(integer) 8
127.0.0.1:6379> get hello
"javapest"
127.0.0.1:6379>
|
小结
| 命令 |
含义 |
时间复杂度 |
| set key value |
设置key-value |
O(1) |
| get key |
获取key-value |
O(1) |
| del key |
删除key-value |
O(1) |
| setnx、setxx |
根据key是否存在设置key-value |
O(1) |
| incr、decr |
计数 |
O(1) |
| mget、mset |
批量获取、设置key-value |
O(n) |
哈希
键值结构
key-value 结构,key 永远是字符串类型;value 分为两个部分,field 和 value,field 表示属性,value 表示具体值。
比如将 user:1:info 作为一个key,用户信息作为值:
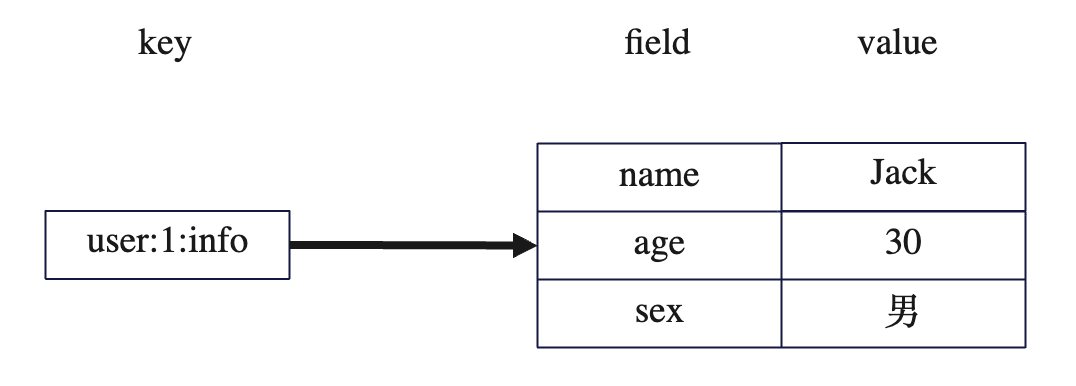
可以往 hash 中添加一个新的值,也就是添加一个新的属性:
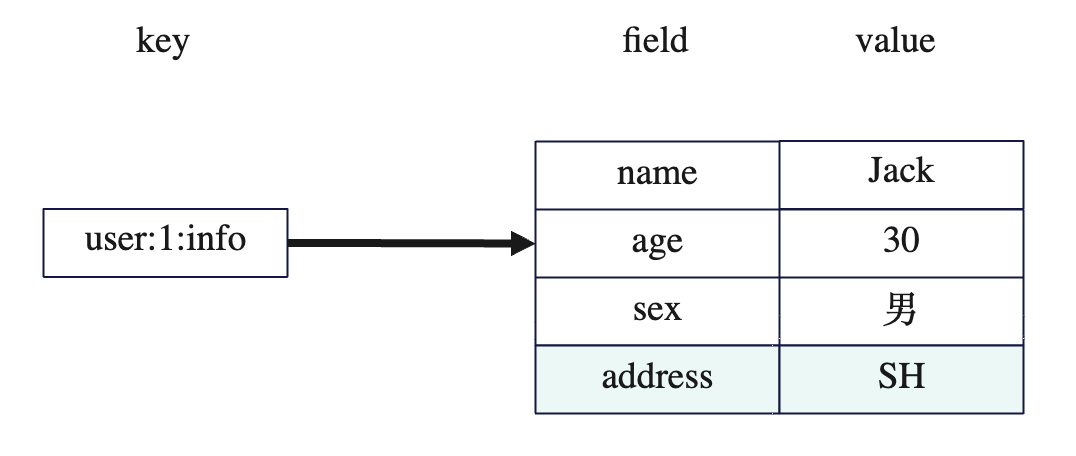
hash 可以把一个key看做是一张表的表名,每个属性可以看做是关系型数据库的一张表的列,值就是每个列对应的值。
Hash 特点是 Mapmap,key-value 的结构,value 又是一个 map的结构,这个map 也是一个key-value。
注意。哈希的value的属性不能相同。
命令
所有hash命令都是以 h 开头。
hget key field:获取hash key 对应的 field 的value,时间复杂度O(1)。
hset key field value:设置hash key 对应的field的value,时间复杂度O(1)。
hdel key field:删除hash key对应的field的value,时间复杂度O(1)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
127.0.0.1:6379> hset user:1:info age 30
(integer) 1
127.0.0.1:6379> hget user:1:info age
"30"
127.0.0.1:6379> hset user:1:info name jack
(integer) 1
# 获取哈希所有属性和值
127.0.0.1:6379> hgetall user:1:info
1) "age"
2) "30"
3) "name"
4) "jack"
127.0.0.1:6379> hdel user:1:info age
(integer) 1
127.0.0.1:6379> hgetall user:1:info
1) "name"
2) "jack"
|
hexists key field:判断hash key是否有field,时间复杂度O(1)。
hlen key:获取hash key field的数量,时间复杂度O(1)。
1
2
3
4
5
6
7
8
9
10
11
|
127.0.0.1:6379> hgetall user:1:info
1) "name"
2) "jack"
3) "age"
4) "30"
127.0.0.1:6379> hexists user:1:info name
(integer) 1
127.0.0.1:6379> hexists user:1:info address
(integer) 0
127.0.0.1:6379> hlen user:1:info
(integer) 2
|
hmget key field1 field2 … fieldN:批量获取hash key的一批field对应的值
hmset key field1 value1 field2 value2 … fieldN valueN:批量设置hash key的一批field value,时间复杂度O(n)。
1
2
3
4
5
6
7
|
127.0.0.1:6379> hmset user:2:info name tom age 20 sex 1
OK
127.0.0.1:6379> hlen user:2:info
(integer) 3
127.0.0.1:6379> hmget user:2:info name age
1) "tom"
2) "20"
|
hgetall:返回hash key对应所有的field和value,时间复杂度O(n)。
hvals key:返回hash key对应的所有field的value,时间复杂度O(n)。
hkeys key:返回hash key对应的所有field,时间复杂度O(n)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
127.0.0.1:6379> hgetall user:2:info
1) "name"
2) "tom"
3) "age"
4) "20"
5) "sex"
6) "1"
127.0.0.1:6379> hvals user:2:info
1) "tom"
2) "20"
3) "1"
127.0.0.1:6379> hkeys user:2:info
1) "name"
2) "age"
3) "sex"
|
hsetnx key field value:设置hash key对应的field的value(如field已经存在,则失败),时间复杂度O(1)。
O(1)
hincrby key field inCounter:hash key对应的field的value自增inCounter,时间复杂度O(1)。
O(1)
hincrbyfloat key field floatCounter:hincrby浮点数版,时间复杂度O(1)。
O(1)
小心使用hgetall
hgetall 会返回所有的field和value,如果hash里面存了很多属性,比如1w条,每次使用hgetall的时候就要注意了,可能会比较慢,因为redis使用的是单线程,一般情况下,不会出现这种需要取出1w条的情况,而是取出部分属性。
小结
string VS hash
| string |
hash |
| get |
hget |
| set、setnx |
hset、hsetnx |
| del |
hdel |
| incr、incrby、decr、decrby |
hincrby |
| mset |
hmset |
| mget |
hmget |
时间复杂度
| 命令 |
时间复杂度 |
| hget、hset、hdel |
O(1) |
| hexists |
O(1) |
| hincrby |
O(1) |
| hgetall、hvals、hkeys |
O(n) |
| hmget、hmset |
O(n) |
列表类型
键值结构
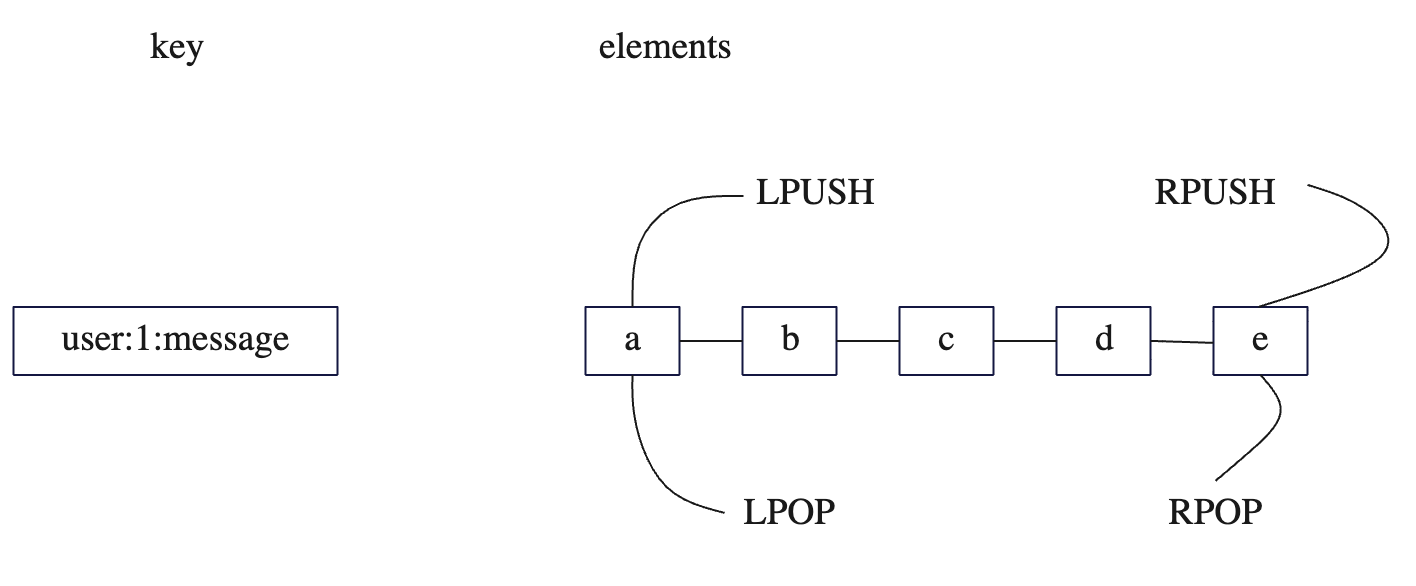
value 是个有序队列,可以进行左边的添加或左边的弹出,右边的添加或右边的弹出。
还可以计算列表的长度,删除列表中指定元素,还可以获取列表中的子列表,还可以根据索引来获取列表指定元素。
列表特点是列表是有序的,可以重复,根据插入的顺序最终决定遍历的顺序,另外还可以左右两边插入弹出。
命令
所有列表命令都是以 l 开头。
rpush key value1 value2 … valueN:从列表右边插入元素(1-N个)。
lpush key value1 value2 … valueN:从列表左边插入元素(1-N个)。
linsert key before|after value newValue:从列表指定的值前|后插入新值。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
127.0.0.1:6379> rpush listkey c b a
(integer) 3
127.0.0.1:6379> lpush listkey c b a
(integer) 6
127.0.0.1:6379> lrange listkey 0 10
1) "a"
2) "b"
3) "c"
4) "c"
5) "b"
6) "a"
# 在第一个满足条件的b之前插入了golang
127.0.0.1:6379> linsert listkey before b golang
(integer) 7
# 在第一个满足条件的b之后插入了php
127.0.0.1:6379> linsert listkey after b php
(integer) 8
127.0.0.1:6379> lrange listkey 0 10
1) "a"
2) "golang"
3) "b"
4) "php"
5) "c"
6) "c"
7) "b"
8) "a"
|
lpop key:从列表左侧弹出一个元素,时间复杂度O(1)。
rpop key:从列表右侧弹出一个元素,时间复杂度O(1)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
127.0.0.1:6379> lpop listkey
"a"
127.0.0.1:6379> lrange listkey 0 10
1) "golang"
2) "b"
3) "php"
4) "c"
5) "c"
6) "b"
7) "a"
127.0.0.1:6379> rpop listkey
"a"
127.0.0.1:6379> lrange listkey 0 10
1) "golang"
2) "b"
3) "php"
4) "c"
5) "c"
6) "b"
127.0.0.1:6379>
|
lrem key count value:根据counte的值,从列表中删除所有与value相等的项:
- count > 0,从左到右,删除最多count个value相等的项
- count < 0,从右到左,删除最多Math.abs(count)个value相等的项
- count = 0,删除所有value相等的项
时间复杂度为O(n)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
127.0.0.1:6379> rpush listkey a c a c b f
(integer) 6
127.0.0.1:6379> lrange listkey 0 19
1) "a"
2) "c"
3) "a"
4) "c"
5) "b"
6) "f"
# 删除所有值为a的元素
127.0.0.1:6379> lrem listkey 0 a
(integer) 2
127.0.0.1:6379> lrange listkey 0 10
1) "c"
2) "c"
3) "b"
4) "f"
# 从右到左,删除值为c的元素
127.0.0.1:6379> lrem listkey -1 c
(integer) 1
127.0.0.1:6379> lrange listkey 0 10
1) "c"
2) "b"
3) "f"
|
ltrim key start end:按照索引范围修剪列表,只保留指定范围内的列表元素。索引从0开始。时间复杂度为O(n)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
127.0.0.1:6379> rpush listkey a b c d e f
(integer) 6
127.0.0.1:6379> lrange listkey 0 10
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
# 保留下标索引为1~4的元素。
127.0.0.1:6379> ltrim listkey 1 4
OK
# 此时索引也发生了变化,
127.0.0.1:6379> lrange listkey 0 10
1) "b"
2) "c"
3) "d"
4) "e"
# 保留索引0~2的元素
127.0.0.1:6379> ltrim listkey 0 2
OK
127.0.0.1:6379> lrange listkey 0 10
1) "b"
2) "c"
3) "d"
|
lrange key start end:包含end,获取列表指定索引范围所有元素。索引从左到右从0开始,索引从右到左从-1开始
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
127.0.0.1:6379> rpush listkey a b c d e f
(integer) 6
127.0.0.1:6379> lrange listkey 0 10
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
# 索引从右到左从-1开始,但是start~end仍然是按小到大的顺序
127.0.0.1:6379> lrange listkey -1 -3
(empty list or set)
127.0.0.1:6379> lrange listkey -3 -1
1) "d"
2) "e"
3) "f"
127.0.0.1:6379> lrange listkey 0 2
1) "a"
2) "b"
3) "c"
127.0.0.1:6379> lrange listkey 0 -1
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
|
lindex key index:获取列表指定索引的元素
1
2
3
4
5
6
7
8
9
10
11
|
127.0.0.1:6379> lrange listkey 0 10
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
127.0.0.1:6379> lindex listkey 0
"a"
127.0.0.1:6379> lindex listkey -1
"f"
|
llen key:获取列表长度
1
2
3
4
5
6
7
8
9
10
11
|
127.0.0.1:6379> lrange listkey 0 10
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
127.0.0.1:6379> lindex listkey -1
"f"
127.0.0.1:6379> llen listkey
(integer) 6
|
lset key index newValue:设置列表指定索引值为newValue
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
127.0.0.1:6379>
127.0.0.1:6379> lrange listkey 0 10
1) "a"
2) "b"
3) "c"
4) "d"
5) "e"
6) "f"
127.0.0.1:6379> lset listkey 2 golang
OK
127.0.0.1:6379> lrange listkey 0 10
1) "a"
2) "b"
3) "golang"
4) "d"
5) "e"
6) "f"
127.0.0.1:6379>
|
blpop key timeout:b表示阻塞,blpop表示阻塞弹出,timeout是阻塞超时时间,timeout=0为永远阻塞,也就是一直死等,一直等到有需要的元素插入然后快速返回,时间复杂度为O(1)。
brpop key timeout:rpop 阻塞版本,timeout是阻塞超时时间,timeout=0为永远阻塞,也就是一直死等,一直等到需要的元素插入然后快速返回,时间复杂度为O(1)。
TIPS
想做一个类似栈或队列的功能,可以参考以下公式:
- LPUSH + LPOP = Stack
- LPUSH + RPOP = Queue
- LPUSH + LTRIM = Capped Collection (固定数量的列表)
- LPUSH +BRPOP = Message Queue
集合类型
键值结构
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着集合中不能出现重复的数据。集合对象的编码可以是 intset 或者 hashtable。Redis 中集合是通过哈希表实现的,所以添加,删除,查找的复杂度都是 O(1)。
命令
所有列表命令都是以 s 开头。
sadd key element:向集合key添加element(如果element已经存在,添加失败)。
srem key element:将集合key中的element移除掉。
Other Command
user:1:follow => it music his sports
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
# 向集合添加元素
127.0.0.1:6379> sadd user:1:follow a b c d
(integer) 4
# 计算集合大小
127.0.0.1:6379> scard user:1:follow
(integer) 4
# 判断元素 b 是否在集合中
127.0.0.1:6379> sismember user:1:follow b
(integer) 1
# 从集合中随机挑count个元素,这是随机挑选2个元素
127.0.0.1:6379> srandmember user:1:follow 2
1) "b"
2) "d"
# 从集合中随机弹出一个元素
127.0.0.1:6379> spop user:1:follow
"d"
# 获取集合所有元素
127.0.0.1:6379> smembers user:1:follow
1) "c"
2) "b"
3) "a"
|
注意
smembers 集合元素是无序的,但是需要小心使用,如果集合元素非常多,可能对阻塞Redis
spop是从集合中弹出元素,每次只弹出一个,srandmember不会破坏集合,并且可以返回多个元素
TIPS
- SADD = Tagging
- SPOP/SRANDMEMBER = Rrandom Item
- SADD + SINTER = Social Graph4
- sdiff|sinter|sunion + store destkey 将差集、交集、并集结果保存在destkey中
有序集合类型
Redis 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员。不同的是每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。有序集合的成员是唯一的,但分数(score)却可以重复。
键值结构
集合 VS 有序集合
| 集合 |
有序集合 |
| 无重复元素 |
无重复元素 |
| 无序 |
有序 |
| element |
score + element |
列表 VS 有序集合
| 列表 |
有序集合 |
| 有重复元素 |
无重复元素 |
| 有序 |
有序 |
| element |
score + element |
命令
所有列表命令都是以 z 开头。
zadd key score element:可以是多对,添加score和element,时间复杂度O(logN)
1
2
3
4
5
|
127.0.0.1:6379> zadd user:1:grade 225 tom
(integer) 1
127.0.0.1:6379> zadd user:1:grade 220 jack
(integer) 1
127.0.0.1:6379>
|
zrem key element(可以是多个):删除元素
1
2
|
127.0.0.1:6379> zrem user:1:grade tom
(integer) 1
|
zscore key element:返回元素的分数
1
2
|
127.0.0.1:6379> zscore user:1:grade tom
"225"
|
zincrby key increScore element:增加或减少元素的分数。
1
2
|
127.0.0.1:6379> zincrby user:1:grade 9 tom
"234"
|
zcard key:返回元素的总个数
1
2
|
127.0.0.1:6379> zcard user:1:grade
(integer) 2
|
zrange key start end [WITHSCORES]:返回指定索引范围内的升序元素[分值]。时间复杂度O(log(n) + m)。
1
2
3
4
|
127.0.0.1:6379> zrange user:1:grade 1 3 withscores
1) "tom"
2) "234"
127.0.0.1:6379>
|
zrangebyscore key minScore maxScore [WITHSCORES]:返回指定分数范围内的升序元素[分值]
1
2
3
4
5
6
|
127.0.0.1:6379> zrangebyscore user:1:grade 40 300 withscores
1) "jack"
2) "220"
3) "tom"
4) "234"
127.0.0.1:6379>
|
zcount key minScore maxScore:返回有序集合内在指定分数范围内的个数。时间复杂度O(log(n) + m)。
1
2
|
127.0.0.1:6379> zcount user:1:grade 200 221
(integer) 1
|
zremrangebyrank key start end:删除指定排名内的升序元素。O(log(n) + m)。
1
2
|
127.0.0.1:6379> zremrangebyrank user:1:grade 1 2
(integer) 1
|
zremrangebyscore key minScore maxScore:删除指定分数内的升序元素时间复杂度O(log(n) + m)。
1
2
|
127.0.0.1:6379> zremrangebyscore user:1:grade 90 230
(integer) 1
|
