持久化作用
什么是持久化
对Redis来说,Redis是将所有数据保存在内存中,如果服务突然崩溃,如果没有将数据保存在磁盘中,数据将会丢失,Redis的持久化是指对数据的更新会异步的保存到磁盘上。磁盘中的数据在关机重启时数据仍然存在。当需要恢复数据时就可以将完整数据加载到内存中。
主流数据库持久化方式
1、快照:可以理解为在某时间点对数据的完整备份。比如MySQL的Dump,Redis的RDB。
2、日志:当数据库发生更新时将对应操作记录到日志,当需要数据恢复时只需将日志进行回放就能获取完整数据的变化。比如MySQL的Binlog,Redis的AOF。
RDB
什么是RDB
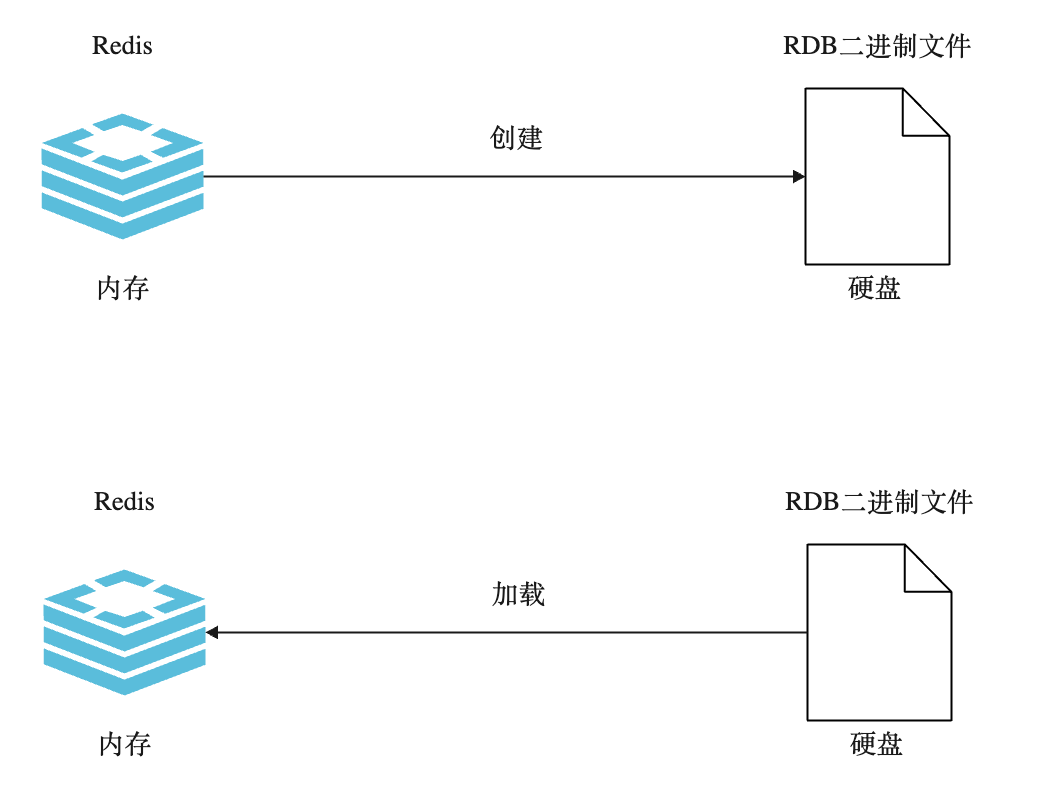
Redis 数据是保存在内存中,通过一条命令将内存中的Redis的数据生成一个快照,保存到一个硬盘中的二进制文件,这个二进制文件就是RDB文件。
当需要对Redis数据进行恢复时,比如机器重启,就可以将RDB文件加载到内存。
RDB的三种触发方式
save:同步命令,在执行该命令之前,其他所有命令都需要排队,等待该命令执行之后再执行其他的命令。也就是,当数据量过大时会造成Redis阻塞
- 策略:如果存在老的RDB文件,新文件会替换旧文件。
- 复杂度:O(n)
bgsave:异步命令,执行完后会立即返回OK,会在后台以单独的进程执行。背后使用了Linux的fork函数,生成了主进程的子进程,让子进程去生成RDB文件。当RDB生成完成后也会告诉主进程RDB生成成功
- 策略:如果存在老的RDB文件,新文件会替换旧文件。
- 复杂度:O(n)
save VS bgsave
| 命令 |
save |
bgsave |
| IO类型 |
同步 |
异步 |
| 是否阻塞 |
是 |
是(阻塞发生在for) |
| 复杂度 |
O(n) |
O(n) |
| 优点 |
不会消耗额外内存 |
不阻塞客户端命令 |
| 缺点 |
阻塞客户端命令 |
需要fork,消耗内存 |
自动生成:在某些条件达到时,自动生成RDB文件。
Redis 提供了自动生成RDB的配置,只要满足下面任一个条件就会触发自动RDB生成,其背后实际也是执行的 bgsave 命令,比如:
| 配置 |
seconds |
changes |
changes |
| save |
900 |
1 |
900秒钟变更了1条数据则自动执行RDB生成 |
| save |
300 |
10 |
300秒钟变更了10条数据则自动执行RDB生成 |
| save |
60 |
10000 |
60秒钟变更了10000条数据则自动执行RDB生成 |
缺点:频率过于频繁,我们无法控制。也可能造成对应硬盘的压力。
配置
- 一般将自动生成配置关闭。
- rdb 文件名:dbfilename dump-${port}.rdb
- 设置较大的硬盘路径,如dir /bigdiskpath
- bgsave发生错误则停止写入,stop-writes-on-bgsave-error yes
- 采用压缩,rdbcompression yes
- 采用校验 rdbchecksum yes
注意
- 全量复制。有时候会发现我们没有执行save、bgsave,也没有配置自动生成,但也能看到rdb文件,这是因为主从复制时主节点会自动生成rdb文件
- debug reload。 可以看做是不将内存数据清空的一次重启。这也会触发RDB文件的生成。
- shutdown。这也会触发RDB文件的生成。
实验
配置如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
# cat redis-6379.conf | grep -v "#" | grep -v "^$"
# 设置后台守护进程启动
daemonize yes
# 设置启动文件
pidfile /var/run/redis-6379.pid
# 配置端口
port 6379
tcp-backlog 511
timeout 0
tcp-keepalive 0
loglevel notice
# 配置日志文件
logfile "6379.log"
databases 16
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
# 配置dbfilename
dbfilename dump-6379.rdb
# 设置数据目录
dir /opt/redis/data
slave-serve-stale-data yes
slave-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
appendonly no
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-entries 512
list-max-ziplist-value 64
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
|
另外注释3行自动生成RDB配置:
1
2
3
4
5
|
...
#save 900 1
#save 300 10
#save 60 10000
...
|
启动redis-server:
1
2
3
4
5
6
7
|
# redis-server redis-6379.conf
# ps -ef | grep redis | grep -v grep
root 451 1 0 10:32 ? 00:00:00 redis-server *:6379
# redis-cli
127.0.0.1:6379> dbsize
(integer) 0
127.0.0.1:6379>
|
使用bash命令中执行下面命令插入10000000条测试数据:
1
2
3
4
5
6
7
|
for ((i=0; i<10000000; i+=10000)); do
redis-cli EVAL "
for j = $i, $((i+9999)) do
redis.call('SET', 'key' .. j, 'value' .. j)
end
" 0
done
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
# redis-cli
127.0.0.1:6379> dbsize
(integer) 10000000
127.0.0.1:6379> info memory
# Memory 已使用1.17G内存
used_memory:1255165992
used_memory_human:1.17G
used_memory_rss:1288101888
used_memory_peak:1316694544
used_memory_peak_human:1.23G
used_memory_lua:791552
mem_fragmentation_ratio:1.03
mem_allocator:jemalloc-3.6.0
127.0.0.1:6379>
|
准备两个终端,一个终端用户执行save命令,另一个终端,先设置一条数据,然后在第一个终端执行RDB生成期间去查询来查询这条数据:
查看 data 目录查看 rdb 文件:
1
2
3
4
5
6
|
# pwd
/opt/redis/data
# ll -lh
total 237M
-rw-r--r-- 1 root root 1.8K 11月 12 15:19 6379.log
-rw-r--r-- 1 root root 237M 11月 12 15:19 dump-6379.rdb
|
当在第一个终端执行 bgsave时,在另一个终端指定命令会发现并不会像执行 save 那样阻塞。
查看下执行 bgsave 后日志:
1
2
3
4
5
|
...
451:M 12 Nov 15:22:58.686 * Background saving started by pid 2393083
2393083:C 12 Nov 15:23:02.671 * DB saved on disk
2393083:C 12 Nov 15:23:02.676 * RDB: 0 MB of memory used by copy-on-write
451:M 12 Nov 15:23:02.688 * Background saving terminated with succes
|
同时查看下是否存在子进程:
1
2
3
|
# ps -ef | grep redis- | grep -v redis-cli | grep -v grep
root 451 1 1 13:21 ? 00:01:49 redis-server *:6379
root 2393094 451 76 15:26 ? 00:00:00 redis-rdb-bgsave *:6379
|
查看文件生成,会看到有个临时文件 temp-2393102.rdb:
1
2
3
4
5
|
# ll -lh
total 292M
-rw-r--r-- 1 root root 2.9K 11月 12 15:28 6379.log
-rw-r--r-- 1 root root 237M 11月 12 15:27 dump-6379.rdb
-rw-r--r-- 1 root root 56M 11月 12 15:28 temp-2393102.rdb
|
接着修改配置文件,配置自动触发RDB生成,只设置60秒内有5个数据更新操作即自动触发:
执行重启操作:
1
2
|
redis-cli shutdown
redis-server redis/config/redis-6379.conf
|
查看日志:
1
2
3
4
5
|
2393125:M 12 Nov 15:34:17.496 * 5 changes in 60 seconds. Saving...
2393125:M 12 Nov 15:34:17.509 * Background saving started by pid 2393137
2393137:C 12 Nov 15:34:21.197 * DB saved on disk
2393137:C 12 Nov 15:34:21.201 * RDB: 0 MB of memory used by copy-on-write
2393125:M 12 Nov 15:34:21.282 * Background saving terminated with success
|
AOF
RDB 存在的问题
| 时间点 |
save |
| T1 |
执行多个写命令 |
| T2 |
满足RDB自动创建条件 |
| T3 |
再次执行多个写命令 |
| T4 |
宕机 |
上面情况在 T3 ~ T4 时间的数据就可能会丢失。
什么是AOF
原理
客户端执行很多写操作的命令,redis会将写命令记录到AOF日志文件中。当Redis宕机需要恢复时,就可以将AOF中记录的数据进行完整恢复。恢复操作基本是实时的。
AOF三种策略
redis 执行写命令实际并不是直接将写命令记录到文件系统(硬盘)中,而是写在硬盘的缓冲区中,缓冲区会根据配置的策略刷新到磁盘中。这么做的目的是为了提高写的效率。
always 是指写入每条命令都会 fsync 到硬盘。这样redis写入的数据就不会丢失。
redis 将命令写入到缓冲区中,每秒都会刷新到磁盘AOF文件中。
将缓冲区刷新到硬盘是由操作系统特性决定。由操作系统决定何时刷新到磁盘AOF文件中。
| 命令 |
always |
everysec |
everysec |
| 优点 |
不丢失数据 |
每秒一次fsync,可能会丢失1秒的数据 |
无需我们关心,又操作系统管理 |
| 缺点 |
IO开销大,一般的磁盘只有几百TPS |
丢1秒数据 |
不可控 |
AOF重写
随着时间的推移,写入命令的增加,AOF文件也会逐渐增大,此时如果使用AOF进行恢复可能会很慢,所以redis提供了AOF重写的机制来解决文件增大的问题。
作用
